Back to IF3130 Sistem Paralel dan Terdistribusi
Topic: Algoritma Pencarian Terdistribusi, DHT, CAN, & Chord
Questions/Cues
Masalah Lookup Terdistribusi
Kelemahan Centralized & Flooding
Prinsip DHT
Consistent Hashing (Solusi Churn)
CAN: Grid & Routing
Chord: Ring Topology
Chord: Successor Definition
Finger Table (Logarithmic Lookup)
Node Join/Leave pada Chord
Reference Points
Slides: Page 18-43
Fokus: Mekanisme Routing & Struktur Data Overlay
1. Evolusi Pencarian Terdistribusi
Tantangan utama dalam sistem peer-to-peer (P2P) adalah menemukan node mana yang menyimpan data
(key, value)secara efisien tanpa bergantung pada server tunggal.A. Generasi 1: Central Coordinator (Napster)
Mekanisme: Menggunakan satu server direktori pusat (indeks). Node melapor ke pusat apa yang mereka punya. Klien bertanya ke pusat untuk mencari lokasi file, lalu mengunduh langsung dari peer (P2P).
Kelemahan Fatal: Single Point of Failure (jika direktori mati, sistem lumpuh), masalah skalabilitas (bottleneck di server pusat), dan kerentanan hukum/serangan.
B. Generasi 2: Query Flooding (Gnutella)
Mekanisme: Murni terdesentralisasi (unstructured overlay). Klien mengirim query ke semua tetangganya (“Punya file X ga?”). Tetangga meneruskan ke tetangganya lagi (flooding) dengan batas Time-to-Live (TTL).
Kelemahan Fatal: Sangat boros bandwidth jaringan karena badai broadcast. Pencarian bisa lambat atau gagal (false negative) jika node pemilik file berada di luar jangkauan TTL.
2. Distributed Hash Tables (DHT)
Solusi Generasi 3 yang menggabungkan efisiensi struktur data Hash Table
O(1)dengan sifat desentralisasi P2P.
Konsep Dasar:
Uniform Hashing: Nama file (Key) dan Alamat Node (IP) dipetakan ke ruang identifier yang sama (misal integer 160-bit) menggunakan fungsi hash seragam (seperti SHA-1).
Mapping Deterministik: Kunci
Kselalu disimpan di node yang ID-nya “paling dekat” denganK(sesuai aturan metrik jarak algoritma).Manfaat: Lookup sangat efisien (biasanya
O(log N)), beban penyimpanan merata (load balancing), dan tidak ada server pusat.Solusi Dinamis: Consistent Hashing
Masalah: Pada hash table biasa (
key % N), jika jumlah nodeNberubah (node masuk/keluar), hampir semua kunci harus dipindahkan (remapping).Solusi: Dengan Consistent Hashing, penambahan/pengurangan node hanya mempengaruhi kunci-kunci di sekitar node tersebut di ruang hash. Hanya sedikit data (
K/n) yang perlu dipindahkan, menjaga stabilitas sistem.3. Implementasi DHT: CAN (Content Addressable Network)
CAN memodelkan ruang kunci sebagai Grid Geometris Cartesian d-dimensi (misal 2D [x,y]).
Zoning: Keseluruhan grid adalah milik sistem. Setiap node “menguasai” satu zona persegi panjang di dalam grid tersebut. Node menyimpan semua data
(k,v)yang hasil hash-nya jatuh di koordinat zonanya.Routing (Greedy):
Node hanya mengetahui “Tetangga” (node yang zonanya bersentuhan langsung secara fisik di grid).
Untuk mengirim pesan ke titik
(x,y), node meneruskan pesan ke tetangga yang koordinatnya paling dekat ke tujuan (meminimalkan jarak Euclidean/Manhattan).Node Join: Node baru memilih titik acak → Node lama pemilik titik tersebut membelah zonanya jadi dua → Setengah diserahkan ke node baru.
4. Implementasi DHT: Chord (Ring Topology)
Chord adalah algoritma DHT paling populer yang menggunakan topologi Cincin Logis (Identifier Circle).
Identifier Space: Node dan Key adalah integer -bit ( s.d. ) yang disusun melingkar.
Aturan Successor: Kunci
kdisimpan di node yang ID-nya sama atau lebih besar pertama dariksearah jarum jam. Node ini disebutsuccessor(k).Mekanisme Lookup (Routing):
Linear Search (Lambat): Setiap node hanya tahu node depannya (
successor). Query diputar keliling cincin sampai ketemu. KompleksitasO(N).Finger Table (Cepat - Logaritmik):
Setiap node menyimpan tabel “jalan pintas” berisi maksimal entri.
Aturan: Entri ke- pada node menunjuk ke node pertama yang jaraknya minimal di depan .
: Jarak (Successor langsung).
: Jarak .
…
: Jarak (Setengah lingkaran).
Algoritma: Saat mencari kunci
k, nodepakan melempar query ke node di Finger Table-nya yang paling dekat dengan k tetapi belum melewatinya (Predecessor terjauh dari k). Ini memangkas jarak pencarian setengah setiap loncatan.Kompleksitas:
O(log N). Sangat scalable untuk jutaan node.5. Manajemen Churn (Node Keluar-Masuk) di Chord
Node Join: Node baru menghitung ID, menghubungi node bootstrap untuk cari posisinya di cincin, lalu mengambil alih sebagian kunci dari successor-nya.
Node Leave/Fail:
Sistem harus tetap jalan meski node mati mendadak.
Replikasi: Setiap kunci tidak hanya disimpan di 1 successor, tapi direplikasi ke successor berikutnya (misal 3 node berurutan).
Stabilisasi: Node secara berkala menjalankan protokol
stabilize()untuk memastikan pointer successor dan finger table-nya akurat.
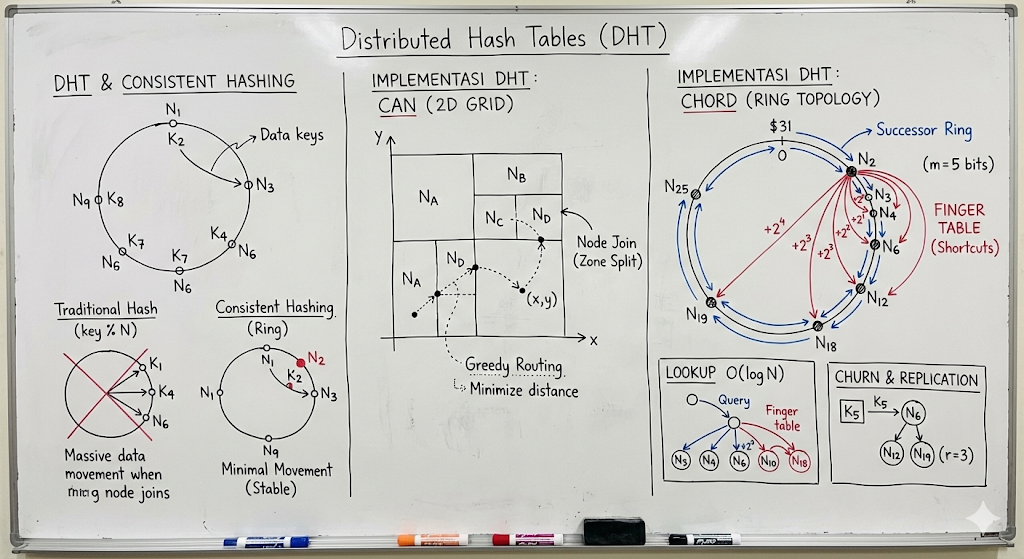
Sistem Pencarian Terdistribusi berevolusi dari model sentral (rawan mati) dan flooding (boros bandwidth) menjadi Distributed Hash Tables (DHT) yang efisien. CAN menggunakan pendekatan grid geometri d-dimensi dengan routing tetangga. Chord menggunakan topologi cincin dengan pointer Successor untuk kepemilikan data dan Finger Table (lompatan eksponensial ) untuk mempercepat lookup menjadi O(log N). Keduanya menggunakan Consistent Hashing untuk meminimalkan perpindahan data saat terjadi perubahan topologi jaringan (churn).
Additional Information (Deep Dive Chord)
Matematika Finger Table Chord
Misalkan panjang identifier bit (0-7). Kita ada di Node 0.
Entri 1: Menunjuk ke
succ(0 + 2^0)=succ(1).Entri 2: Menunjuk ke
succ(0 + 2^1)=succ(2).Entri 3: Menunjuk ke
succ(0 + 2^2)=succ(4).Jika kita ingin mencari Kunci 6, Node 0 melihat tabelnya. Entri terjauh yang ⇐ 6 adalah Entri 3 (Node 4). Query langsung loncat ke Node 4. Dari Node 4, mungkin successor-nya langsung memegang kunci 6.
Fault Tolerance Detail
Slide menekankan bahwa setiap node harus tahu “Successor-nya Successor” (Successor List). Jika successor langsung mati, node bisa melompati node mati itu dan menghubungi successor berikutnya dalam daftar, lalu memperbaiki topologi cincin secara otomatis.
Sumber & Referensi:
Paper: Stoica, I., et al. (2001). “Chord: A scalable peer-to-peer lookup service for internet applications”. SIGCOMM.
Paper CAN: Ratnasamy, S., et al. (2001). “A Scalable Content-Addressable Network”. SIGCOMM.
Spaced Repetition Questions (Review)
1. Mengapa pencarian data di Gnutella (Flooding) dianggap tidak scalable?
Karena jumlah pesan query meningkat secara eksponensial seiring bertambahnya jumlah hop (tetangga meneruskan ke semua tetangga), menghabiskan bandwidth jaringan, dan tidak