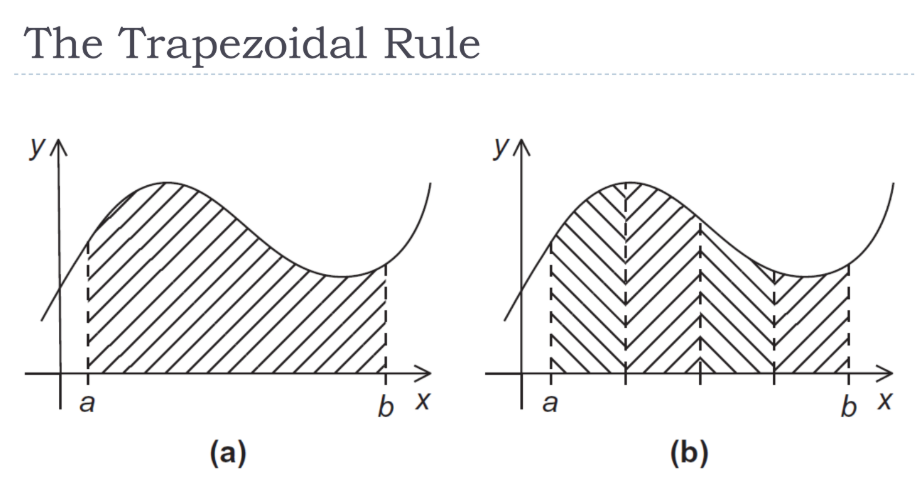
Aturan Trapesium adalah sebuah metode numerik untuk menghitung integral definit, yaitu mencari luas di bawah kurva.
Konsep Serial: Area di bawah kurva dari titik a ke b diaproksimasi dengan membaginya menjadi n buah trapesium kecil dengan lebar yang sama, h. Luas total adalah jumlah dari luas semua trapesium tersebut.
Rumus: Luas ≈ h×[2f(x0)+f(xn)+∑i=1n−1f(xi)]
Paralelisasi Aturan Trapesium
Proses untuk mengubah algoritma serial menjadi paralel mengikuti empat langkah utama:
Partition (Partisi): Bagi total n trapesium menjadi beberapa bagian kecil. Setiap proses akan bertanggung jawab untuk menghitung sebagian dari total luas.
Communication (Komunikasi): Tentukan data apa yang perlu dibagikan antar proses. Dalam kasus ini, proses pekerja perlu mengirimkan hasil perhitungan parsial mereka ke satu proses utama.
Aggregation (Agregasi): Gabungkan tugas-tugas kecil. Proses utama (biasanya rank 0) akan menerima semua hasil parsial dan menjumlahkannya untuk mendapatkan hasil akhir.
Mapping (Pemetaan): Petakan tugas yang sudah diagregasi ke setiap proses (core).
Pembagian Kerja (Work Distribution)
Total n trapesium dibagi rata ke comm_sz (jumlah proses). Setiap proses menghitung local_n = n / comm_sz trapesium.
Rentang integrasi untuk setiap proses ditentukan berdasarkan rank-nya:
local_a = a + my_rank * local_n * h; (Titik awal lokal)
local_b = local_a + local_n * h; (Titik akhir lokal)
Dengan cara ini, setiap proses menghitung local_int (integral lokal) pada sub-intervalnya masing-masing secara independen dan bersamaan.
Penggabungan Hasil (Result Aggregation)
Setelah setiap proses selesai menghitung integral lokalnya, hasilnya harus digabungkan. Pola yang umum adalah:
Proses Pekerja (my_rank != 0): Mengirim nilai local_int mereka ke proses 0 menggunakan MPI_Send.
Proses Master (my_rank == 0):
Menginisialisasi total_int dengan nilai local_int miliknya sendiri.
Masuk ke dalam sebuah loop untuk menerima local_int dari semua proses lain (dari rank 1 hingga comm_sz - 1) menggunakan MPI_Recv.
Menambahkan setiap nilai yang diterima ke total_int.
Setelah loop selesai, proses 0 memiliki hasil integral total dan dapat mencetaknya.
Kode dalam C
int main(void) { int my_rank, comm_sz, n = 1024, local_n; double a = 0.0, b = 3.0, h, local_a, local_b; double local_int, total_int; int source; // Initialize MPI environment MPI_Init(NULL, NULL); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Comm_size(MPI_COMM_WORLD, &comm_sz); // Calculate interval parameters for each process h = (b-a)/n; /* Step size is the same for all processes */ local_n = n/comm_sz; /* Number of trapezoids per process */ // Determine local integration bounds for each process local_a = a + my_rank*local_n*h; local_b = local_a + local_n*h; local_int = Trap(local_a, local_b, local_n, h); // Process 0 collects results from all other processes if (my_rank != 0) { MPI_Send(&local_int, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); } else { total_int = local_int; // Receive partial integrals from all other processes for (source = 1; source < comm_sz; source++) { MPI_Recv(&local_int, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); total_int += local_int; } } // Display final result if (my_rank == 0) { printf("With n = %d trapezoids, our estimate\n", n); printf("of the integral from %f to %f = %.15e\n", a, b, total_int); } MPI_Finalize(); return 0;} /* main */
Trapezoidal Rule Function
double Trap( double left_endpt /* in */, double right_endpt /* in */, int trap_count /* in */, double base_len /* in */) { double estimate, x; int i; // Apply trapezoidal rule: average of endpoints plus sum of intermediate points estimate = (f(left_endpt) + f(right_endpt))/2.0; for (i = 1; i <= trap_count-1; i++) { x = left_endpt + i*base_len; estimate += f(x); } estimate = estimate*base_len; return estimate;} /* Trap */
Penanganan Input/Output (I/O)
I/O dalam program paralel memerlukan perhatian khusus karena sifatnya yang non-deterministik.
Output: Jika setiap proses memanggil printf secara bersamaan, urutan pesan yang muncul di layar tidak dapat diprediksi. Sistem operasi dapat menjalankan proses dalam urutan apa pun, sehingga output dari proses 4 bisa muncul sebelum proses 2.
Input: Sebagian besar implementasi MPI hanya mengizinkan proses 0 yang terhubung ke stdin. Artinya, hanya proses 0 yang bisa membaca input dari keyboard (scanf). Oleh karena itu, strategi standarnya adalah:
Proses 0 membaca semua data input yang diperlukan (misalnya, nilai a, b, dan n).
Proses 0 kemudian mendistribusikan data ini ke semua proses lain menggunakan MPI_Send dalam sebuah loop.
Proses-proses lain (rank != 0) memanggil MPI_Recv untuk menerima data yang dikirim oleh proses 0.
Contoh Kode:
void Get_input( int my_rank /* in */, int comm_sz /* in */, double* a_p /* out */, double* b_p /* out */, int* n_p /* out */) { int dest; // Process 0 reads input and broadcasts to all other processes if (my_rank == 0) { printf("Enter a, b, and n\n"); scanf("%lf %lf %d", a_p, b_p, n_p); // Send input parameters to all other processes for (dest = 1; dest < comm_sz; dest++) { MPI_Send(a_p, 1, MPI_DOUBLE, dest, 0, MPI_COMM_WORLD); MPI_Send(b_p, 1, MPI_DOUBLE, dest, 0, MPI_COMM_WORLD); MPI_Send(n_p, 1, MPI_INT, dest, 0, MPI_COMM_WORLD); } } else { /* my_rank != 0 */ // Receive input parameters from process 0 MPI_Recv(a_p, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); MPI_Recv(b_p, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); MPI_Recv(n_p, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); }} /* Get_input */
Summary
Aplikasi praktis MPI pada masalah komputasi seperti Aturan Trapesium dilakukan dengan mempartisi domain masalah, di mana setiap proses secara paralel menghitung hasil parsial (local_integral) pada sub-domainnya. Hasil-hasil ini kemudian diagregasi oleh satu proses master (rank 0) menggunakan komunikasi point-to-point (MPI_Send/MPI_Recv). Penanganan I/O memerlukan strategi terkoordinasi di mana hanya proses 0 yang membaca input dari stdin dan kemudian mendistribusikannya ke semua proses lain untuk memastikan semua memiliki data awal yang sama.
Additional Information
Masalah Pembagian Kerja: Load Imbalance
Dalam contoh ini, kita mengasumsikan n habis dibagi oleh comm_sz. Bagaimana jika tidak? Misal, 1025 trapesium dan 8 proses. 1025 / 8 bukanlah bilangan bulat. Jika kita hanya menggunakan pembagian integer (1025 / 8 = 128), maka 1 trapesium akan terlewat. Strategi yang lebih baik adalah:
Hitung sisa pembagian: remainder = n % comm_sz.
Bagikan sisa tersebut ke remainder proses pertama.
Jadi, remainder proses pertama mengerjakan n/comm_sz + 1 bagian, dan sisanya mengerjakan n/comm_sz bagian.
Ini adalah bentuk sederhana dari load balancing (penyeimbangan beban kerja) untuk memastikan semua pekerjaan diselesaikan dan didistribusikan seadil mungkin.
Keterbatasan Agregasi dengan Loop
Menggunakan loop for di proses 0 untuk menerima hasil satu per satu dari proses lain bersifat sekuensial dan bisa menjadi bottleneck (penghambat) jika jumlah proses sangat banyak. Proses 0 harus menunggu setiap proses secara berurutan. Ini adalah salah satu motivasi utama untuk menggunakan komunikasi kolektif (seperti MPI_Reduce yang akan dibahas nanti), di mana operasi agregasi (seperti penjumlahan) dapat dilakukan secara lebih efisien dengan pola komunikasi berbentuk pohon, mengurangi waktu tunggu di proses master.
Eksplorasi Mandiri
Modifikasi Kode: Coba ubah kode Aturan Trapesium untuk menangani kasus di mana n tidak habis dibagi comm_sz menggunakan strategi load balancing yang dijelaskan di atas.
Implementasi Aturan Simpson: Aturan Simpson adalah metode integrasi numerik lain yang lebih akurat. Coba implementasikan versi paralel dari Aturan Simpson menggunakan pola pembagian kerja dan agregasi yang sama.
Sumber & Referensi Lanjutan:
Buku: “Numerical Recipes in C: The Art of Scientific Computing” oleh Press, Teukolsky, Vetterling, dan Flannery memberikan pembahasan mendalam tentang berbagai metode numerik termasuk integrasi.
Topik Pencarian: “Parallel numerical integration”, “Load balancing strategies in HPC”.