Back to IF3130 Sistem Paralel dan Terdistribusi
Topic
Questions/Cues
Apa itu Instruction Level Parallelism (ILP)?
Apa itu Pipelining?
Apa itu Multiple issue?
Apa itu Hardware Multithreading?
Apa saja 4 kategori Taksonomi Flynn?
Apa itu arsitektur SIMD?
Apa itu Vector Processor & GPU?
Apa itu arsitektur MIMD?
Apa beda Shared vs Distributed Memory?
Apa itu UMA & NUMA?
Apa masalah Cache Coherence?
Reference Points
- Slides IF3230-02-ParallelHardware-Software-2022.pdf
Paralelisme Level Instruksi (ILP)
ILP adalah sekumpulan teknik yang digunakan prosesor untuk mengeksekusi beberapa instruksi secara bersamaan dalam satu core. Tujuannya adalah untuk meningkatkan performa tanpa harus menunggu satu instruksi selesai sepenuhnya sebelum memulai yang berikutnya.
- Pipelining: Memecah proses eksekusi sebuah instruksi menjadi beberapa tahapan (seperti jalur perakitan). Saat tahap pertama dari instruksi A selesai, tahap pertama dari instruksi B bisa langsung dimulai tanpa menunggu seluruh instruksi A selesai. Ini memungkinkan banyak instruksi berada dalam berbagai tahap eksekusi secara bersamaan.
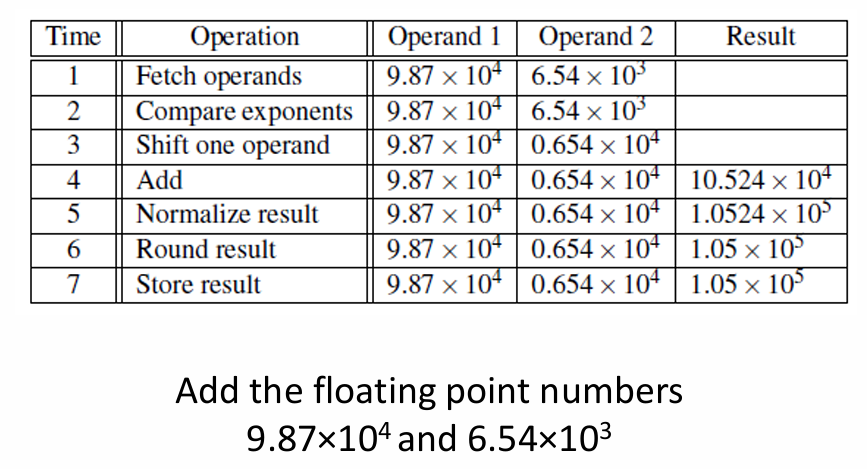
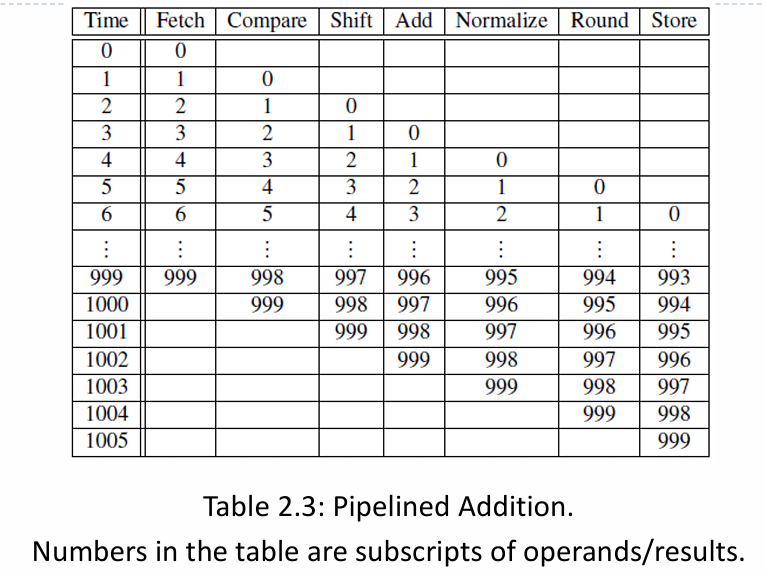
Contoh: Misalkan operasi penjumlahan floating point membutuhkan 7 tahap (Fetch, Compare, Shift, Add, Normalize, Round, Store), dan setiap tahap butuh 1 nanosekon.
Tanpa Pipelining: Satu penjumlahan butuh 7 ns. Untuk menjumlahkan 1000 pasang angka (
for i=0 to 999, z[i]=x[i]+y[i]), total waktu yang dibutuhkan adalah1000 * 7 ns = 7000 ns.Dengan Pipelining: Hasil pertama keluar pada nanosekon ke-7. Namun, hasil kedua keluar pada nanosekon ke-8, hasil ketiga pada nanosekon ke-9, dan seterusnya. Total waktu untuk 1000 penjumlahan menjadi
7 ns (untuk hasil pertama) + 999 ns (untuk 999 hasil berikutnya) = 1006 ns. Ini adalah percepatan hampir 7x lipat.
- Multiple Issue: Menyediakan beberapa unit eksekusi fungsional (misalnya, beberapa unit penambahan) sehingga prosesor dapat memulai eksekusi beberapa instruksi yang tidak saling bergantung dalam satu siklus clock yang sama.
- Contoh: Pada loop
z[i]=x[i]+y[i], jika prosesor memiliki dua unit penambahan (adder), ia bisa menghitungz[0]=x[0]+y[0]danz[1]=x[1]+y[1]pada saat yang bersamaan.- Jenis: Static Multiple Issue (penjadwalan instruksi dilakukan oleh compiler saat kompilasi) dan Dynamic Multiple Issue atau Superscalar (penjadwalan dilakukan oleh hardware saat eksekusi).
- Teknik ini akan terhenti (stall) saat menghadapi percabangan (
if-else) karena prosesor tidak tahu jalur mana yang harus dieksekusi. Untuk mengatasinya, digunakan spekulasi: prosesor “menebak” hasil dari percabangan dan mulai mengeksekusi instruksi di jalur yang paling mungkin agar unit eksekusi tidak menganggur.
- Contoh:
Hardware Multithreading
Teknik ini memungkinkan satu core prosesor untuk menangani beberapa threads (alur eksekusi) secara bersamaan. Tujuannya adalah untuk menjaga core tetap sibuk. Jika satu thread berhenti (misalnya, menunggu data dari memori), core dapat langsung beralih mengerjakan thread lain.
Fine-grained: Beralih antar thread setelah setiap instruksi.
- Pro: Berpotensi untuk menghindari waktu mesin yang terbuang karena stall.
- Kontra: Sebuah thread yang siap mengeksekusi banyak instruksi berurutan mungkin harus menunggu giliran untuk setiap instruksinya, sehingga bisa jadi malah melambat.
Coarse-grained: Hanya beralih thread saat terjadi jeda yang panjang (misalnya, cache miss).
- Pro: Proses peralihan tidak harus secepat kilat, sehingga overhead-nya lebih kecil.
- Kontra: Prosesor bisa tetap menganggur saat terjadi jeda-jeda singkat, dan proses peralihan itu sendiri juga menimbulkan sedikit penundaan.
Simultaneous Multithreading (SMT): Dikenal sebagai Hyper-Threading oleh Intel. Ini adalah variasi dari fine-grained multithreading yang memungkinkan beberapa thread untuk menggunakan unit-unit eksekusi fungsional yang berbeda di dalam satu core pada saat yang bersamaan. Ini memaksimalkan utilisasi hardware di dalam core.
Taksonomi Flynn
Ini adalah klasifikasi klasik untuk arsitektur komputer berdasarkan jumlah alur instruksi (instruction stream) dan alur data (data stream).
SISD (Single Instruction, Single Data): Komputer sekuensial tradisional. Satu instruksi memproses satu data pada satu waktu.
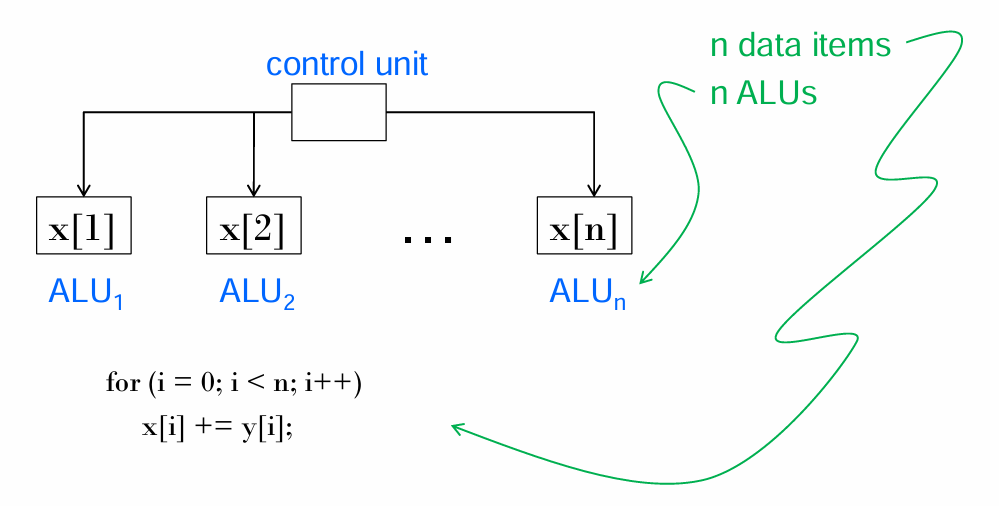
SIMD (Single Instruction, Multiple Data): Satu instruksi dieksekusi secara serentak pada banyak data yang berbeda. Ini adalah inti dari data parallelism.
MISD (Multiple Instruction, Single Data): Beberapa instruksi berbeda beroperasi pada data yang sama. Sangat jarang diimplementasikan.
MIMD (Multiple Instruction, Multiple Data): Beberapa instruksi berbeda secara serentak memproses beberapa data yang berbeda. Ini adalah arsitektur yang paling umum untuk komputer paralel modern (multicore).
Arsitektur SIMD: Vector Processor dan GPU
Arsitektur SIMD adalah perwujudan data parallelism, di mana satu instruksi diterapkan ke banyak data sekaligus. Arsitektur SIMD sangat efisien untuk tugas-tugas yang repetitif pada data dalam jumlah besar.
Model SIMD ini memiliki beberapa kelemahan, yakni tidak fleksibel (semua ALU harus seragam atau diam), harus sinkron, dan terbatas hanya untuk masalah data-parallel yang seragam. Perlu diingat juga bahwa ALU tidak mempunyai kemampuan menyimpan data.
Untuk itu, terdapat dua modifikasi SIMD yang mencoba mengatasi hal tersebut:
Vector Processors: CPU khusus yang memiliki instruksi yang dapat melakukan satu operasi (misalnya, penjumlahan) pada seluruh larik (vektor) data sekaligus.
- Fitur: Memiliki Vector Registers, Pipelined Units, Vector Instructions, dan Interleaved Memory.
- Kelebihan: Sangat cepat, mudah digunakan karena adanya vectorizing compilers, dan punya bandwidth memori tinggi.
- Kekurangan: Kurang fleksibel untuk struktur data tidak teratur dan skalabilitasnya terbatas.
GPU (Graphics Processing Unit): Berevolusi menjadi prosesor paralel masif dengan ribuan core sederhana, ideal untuk mengeksekusi instruksi yang sama pada ribuan data secara bersamaan.
- Cara Kerja: GPU menggunakan pipeline grafis untuk mengubah representasi internal objek (titik, garis, segitiga) menjadi piksel di layar. Beberapa tahapan pipeline ini, yang disebut shader functions, dapat diprogram. Fungsi-fungsi ini bersifat implisit paralel karena diterapkan pada ribuan elemen (misalnya, piksel) secara bersamaan, yang pada dasarnya adalah operasi SIMD.
- Arsitektur: Terdiri dari ribuan core sederhana, ideal untuk mengeksekusi instruksi yang sama pada ribuan data secara bersamaan.
- Jenis:
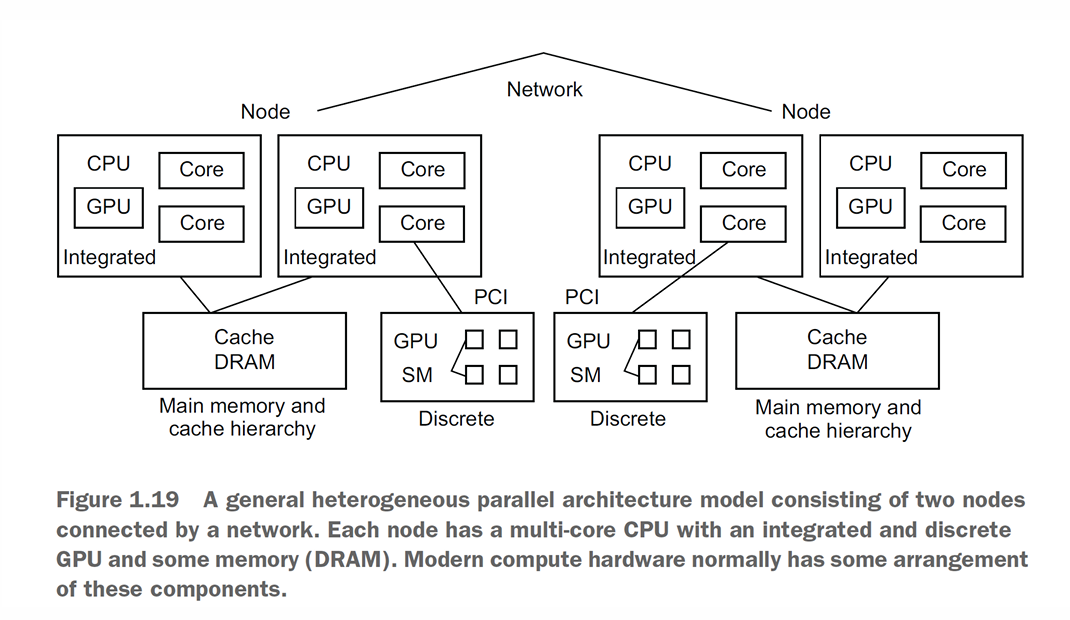
Integrated: GPU berada dalam satu chip yang sama dengan CPU.
Discrete: GPU berada di kartu grafis terpisah, memiliki memorinya sendiri (DRAM), dan terhubung ke CPU melalui bus PCI. Komunikasi melalui bus ini menimbulkan overhead.
Arsitektur MIMD: Otak dari Komputasi Paralel Modern
Sistem MIMD terdiri dari banyak unit pemrosesan yang sepenuhnya independen, masing-masing dengan unit kontrol dan ALU-nya sendiri.
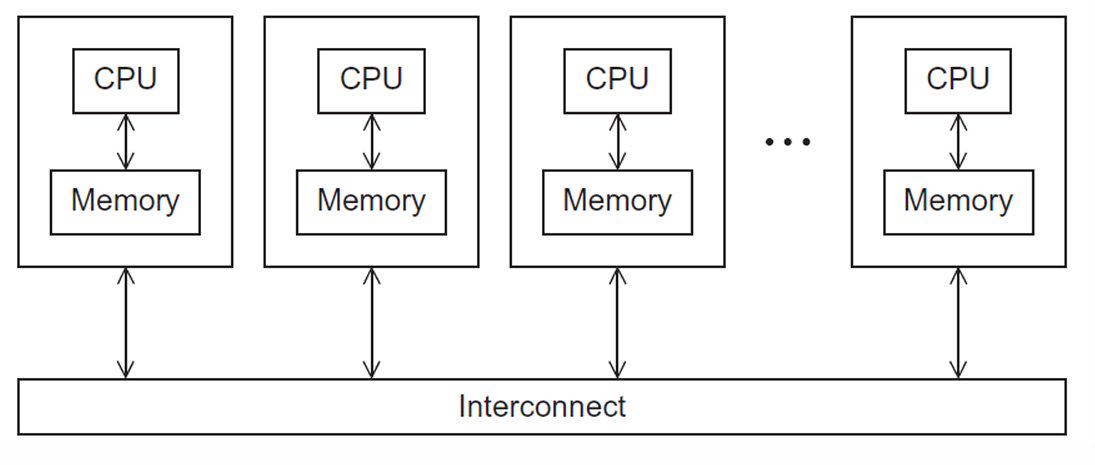
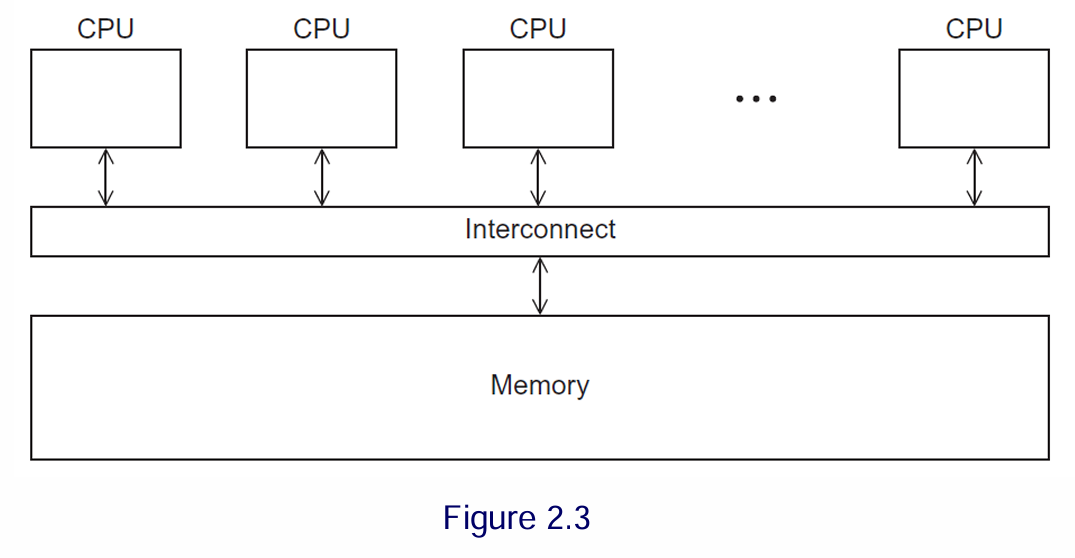
Shared-Memory Systems
Konsep: Semua prosesor/core terhubung ke satu ruang memori utama (RAM) yang sama.
Jenis:
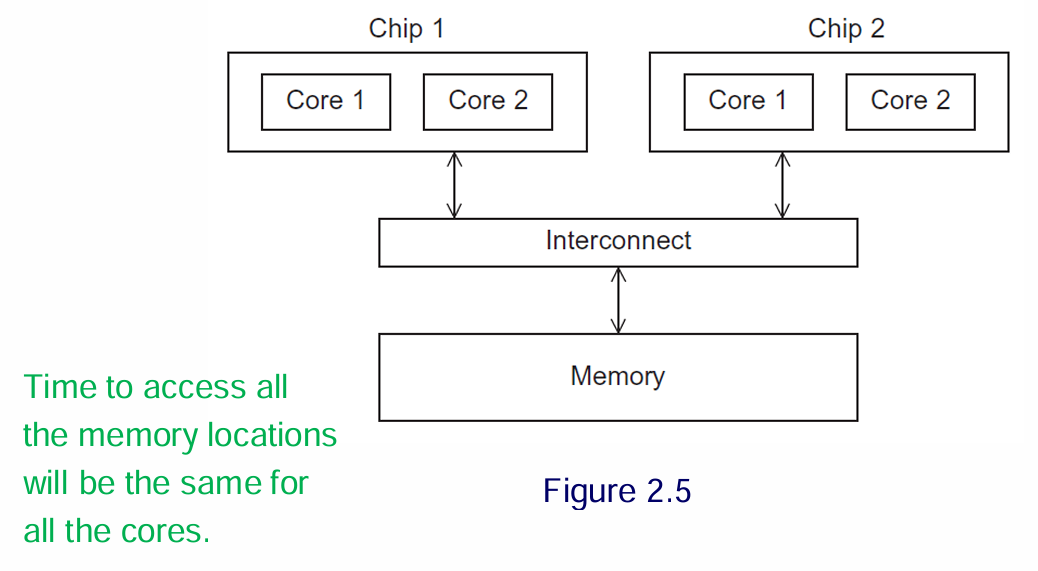
UMA (Uniform Memory Access): Waktu yang dibutuhkan setiap core untuk mengakses lokasi memori mana pun adalah sama. Umum pada PC dan laptop multicore.
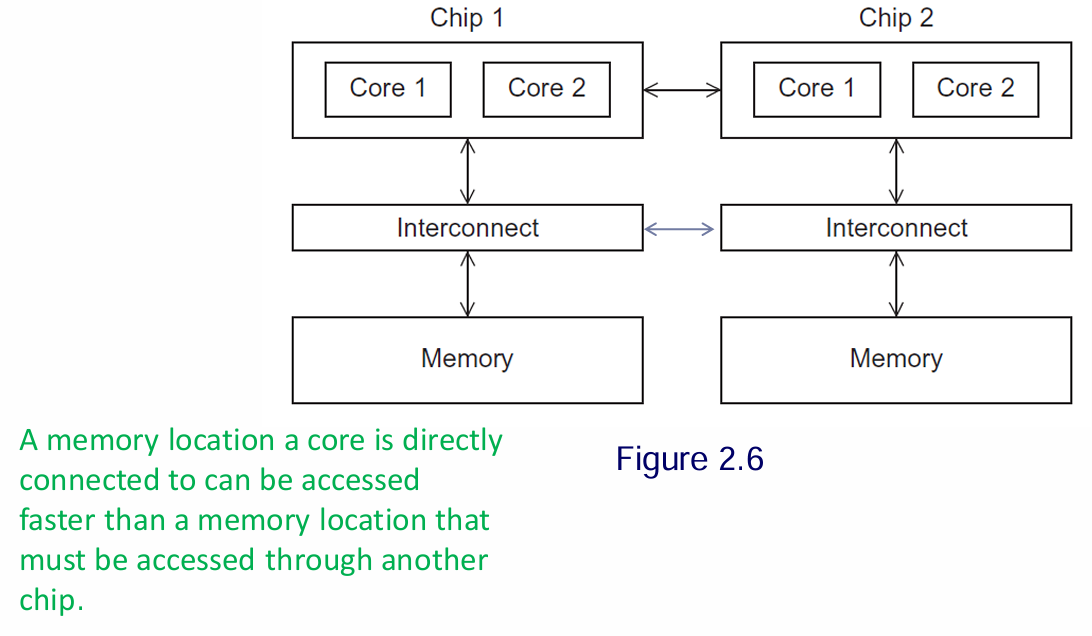
NUMA (Non-Uniform Memory Access): Terdiri dari beberapa chip prosesor. Sebuah core dapat mengakses memori yang terhubung langsung dengannya lebih cepat daripada memori yang terhubung ke chip lain.
Distributed-Memory Systems
Konsep: Setiap prosesor memiliki memorinya sendiri yang bersifat privat. Tidak ada prosesor yang dapat mengakses memori milik prosesor lain secara langsung.
Komunikasi: Prosesor harus berkomunikasi secara eksplisit melalui jaringan interkoneksi untuk bertukar data.
Implementasi Umum: Cluster, yaitu kumpulan komputer komoditas (disebut node) yang dihubungkan oleh jaringan berkecepatan tinggi.


Arsitektur hardware paralel modern menggunakan berbagai strategi berlapis, mulai dari mengeksekusi beberapa instruksi dalam satu core (ILP, SMT) hingga menggunakan banyak core dalam satu sistem (MIMD). Sistem ini secara fundamental dibedakan oleh model memorinya: sistem Shared-Memory (seperti UMA dan NUMA) memungkinkan komunikasi implisit melalui memori bersama, yang menimbulkan tantangan Cache Coherence. Sebaliknya, sistem Distributed-Memory (seperti cluster) menuntut komunikasi eksplisit antar prosesor melalui jaringan. Arsitektur khusus seperti GPU juga memainkan peran penting dengan menyediakan kemampuan SIMD secara masif untuk tugas data-parallel.
Additional Information
Analogi Sederhana: Tim Penulis di Google Docs vs. Email
Shared-Memory (Google Docs): Semua penulis (cores) bekerja pada satu dokumen yang sama (shared memory). Perubahan yang dibuat oleh satu penulis akan langsung terlihat oleh yang lain. Ini sangat efisien, tetapi bisa menimbulkan masalah jika dua orang mengedit kalimat yang sama secara bersamaan (race condition dan cache coherence).
Distributed-Memory (Email): Setiap penulis (processor) memiliki salinan drafnya sendiri (local memory). Untuk berkolaborasi, mereka harus secara eksplisit mengirimkan versi terbaru draf mereka melalui email (message passing) kepada yang lain. Tidak ada risiko dua orang mengedit kalimat yang sama secara bersamaan, tetapi ada overhead dari proses mengirim dan menerima email.
Eksplorasi Mandiri
- Cari Tahu Topologi Jaringan Superkomputer: Cari di internet “Top500 Supercomputers”. Pilih salah satu superkomputer teratas dan cari tahu jenis jaringan interkoneksi yang digunakannya (misalnya, InfiniBand, Slingshot, dll.). Ini akan memberi Anda gambaran tentang betapa pentingnya “sistem peredaran darah” pada sistem skala besar.