Mengapa komunikasi point-to-point tidak efisien untuk agregasi?
Apa itu komunikasi tree-structured?
Bagaimana MPI_Reduce bekerja?
Apa bedanya MPI_Reduce dan MPI_Allreduce?
Untuk apa MPI_Bcast digunakan?
Apa saja aturan penting dalam komunikasi kolektif?
Reference Points
Slides 41-59
Keterbatasan Komunikasi Point-to-Point
Pada catatan sebelumnya, proses 0 mengumpulkan hasil dari proses lain satu per satu dalam sebuah loop. Metode ini memiliki kelemahan:
Bottleneck: Proses 0 menjadi titik hambatan karena harus berkomunikasi dengan setiap proses lain secara sekuensial.
Tidak Efisien: Jika ada banyak proses, waktu yang dihabiskan untuk komunikasi serial ini bisa sangat signifikan, mengurangi keuntungan dari paralelisasi.
Komunikasi Kolektif
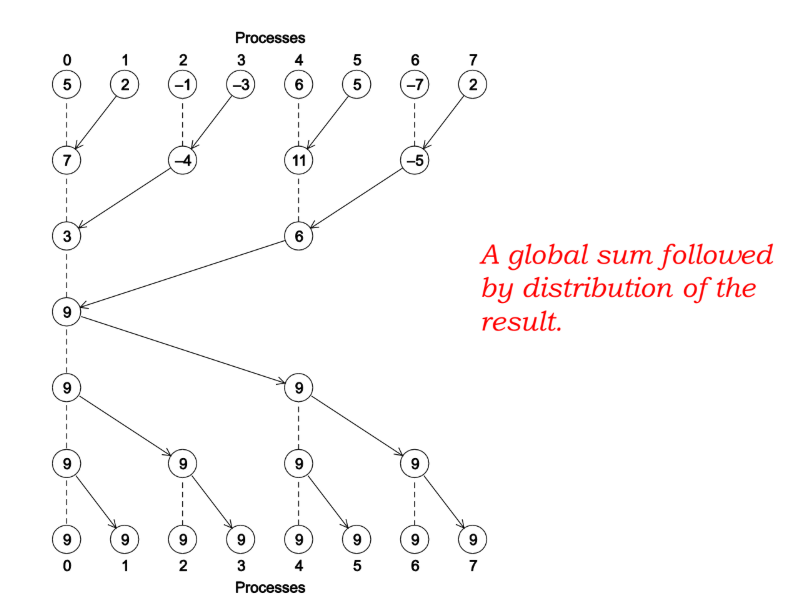
Komunikasi kolektif adalah operasi di mana semua proses dalam sebuah komunikator berpartisipasi secara serentak. Ini jauh lebih efisien untuk operasi global (seperti menjumlahkan semua hasil) karena implementasi MPI biasanya menggunakan algoritma cerdas seperti komunikasi berbentuk pohon (tree-structured).
Komunikasi Tree-Structured: Daripada semua mengirim ke satu titik, proses diatur dalam sebuah hierarki. Proses-proses di level bawah mengirimkan data ke “partner” mereka di level atas, yang kemudian melakukan agregasi parsial dan meneruskannya ke level yang lebih atas lagi. Ini mengurangi beban pada satu proses dan memanfaatkan paralelisme dalam jaringan komunikasi itu sendiri.
Agregasi Global: MPI_Reduce
MPI_Reduce adalah fungsi kolektif yang mengambil data dari setiap proses, melakukan operasi reduksi (misalnya, penjumlahan, mencari nilai maksimum), dan menyimpan hasil akhirnya di satu proses tujuan.
int MPI_Reduce( void* input_data_p, void* output_data_p, int count, MPI_Datatype datatype, MPI_Op operator, int dest_process, MPI_Comm comm);
input_data_p: Pointer ke data lokal yang akan dikontribusikan setiap proses.
output_data_p: Hanya signifikan di dest_process. Pointer ke memori untuk menyimpan hasil akhir.
count: Jumlah elemen data.
operator: Operasi yang akan dilakukan, misalnya MPI_SUM, MPI_MAX, MPI_MIN.
dest_process: Rank dari proses yang akan menyimpan hasil akhir.
Contoh:MPI_Reduce(&local_int, &total_int, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); akan menjumlahkan semua local_int dan menyimpan hasilnya di total_int pada proses 0.
Scenario: Multiple MPI_Reduce Calls
Initial State
Process 0: a = 1, c = 2
Process 1: a = 1, c = 2
Process 2: a = 1, c = 2
Time
Process 0
Process 1
Process 2
0
a = 1; c = 2
a = 1; c = 2
a = 1; c = 2
1
MPI_Reduce(&a, &b, ...)
MPI_Reduce(&c, &d, ...)
MPI_Reduce(&a, &b, ...)
2
MPI_Reduce(&c, &d, ...)
MPI_Reduce(&a, &b, ...)
MPI_Reduce(&c, &d, ...)
Jika kita berpikir sederhana:
Reduce 1: Sum dari semua a → b = 1+1+1 = 3
Reduce 2: Sum dari semua c → d = 2+2+2 = 6
PADAHAL…Key Point: MPI menggunakan call order matching, bukan variable name matching.
Time 1:
Process 0: Memanggil MPI_Reduce(&a, &b, ...) (Call #1)
Process 1: Memanggil MPI_Reduce(&c, &d, ...) (Call #1)
Process 2: Memanggil MPI_Reduce(&a, &b, ...) (Call #1)
MPI matching: Semua call #1 dicocokkan bersama
Input values: 1 (P0) + 2 (P1) + 1 (P2) = 4
Result di Process 0: b = 4
Time 2:
Process 0: Memanggil MPI_Reduce(&c, &d, ...) (Call #2)
Process 1: Memanggil MPI_Reduce(&a, &b, ...) (Call #2)
Process 2: Memanggil MPI_Reduce(&c, &d, ...) (Call #2)
MPI matching: Semua call #2 dicocokkan bersama
Input values: 2 (P0) + 1 (P1) + 2 (P2) = 5
Result di Process 0: d = 5
Final Results
Process 0: b = 4, d = 5
Poin Penting
1. Order-Based Matching
MPI_Reduce mencocokkan calls berdasarkan urutan pemanggilan, bukan nama variabel:
Call ke-1 dari semua proses dicocokkan
Call ke-2 dari semua proses dicocokkan
2. Synchronization Point
Setiap MPI_Reduce adalah blocking collective operation:
Semua proses harus mencapai call yang sama
Tidak ada proses yang bisa melanjutkan sampai operasi selesai
3. Communication Tag
MPI secara internal menggunakan implicit tag berdasarkan urutan call untuk membedakan operasi.
Best Practices
DO: Consistent Call Order
// Semua proses memanggil dalam urutan yang samaMPI_Reduce(&local_a, &global_a, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);MPI_Reduce(&local_b, &global_b, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
DON’T: Different Call Order
// Process 0MPI_Reduce(&a, &result1, ...);MPI_Reduce(&b, &result2, ...);// Process 1MPI_Reduce(&b, &result1, ...); // ← Akan dicocokkan dengan call pertama P0MPI_Reduce(&a, &result2, ...); // ← Akan dicocokkan dengan call kedua P0
Solusi untuk Konsistensi
Gunakan urutan call yang sama di semua proses
Gunakan MPI_Allreduce jika semua proses butuh hasil
Gabungkan data dalam satu array lalu reduce sekali
Gunakan MPI tags eksplisit dengan operasi point-to-point jika perlu kontrol lebih
Catatan: Ini adalah behavior standar MPI dan berlaku untuk semua operasi kolektif (Reduce, Allreduce, Broadcast, dll.).
Agregasi & Distribusi: MPI_Allreduce
MPI_Allreduce mirip dengan MPI_Reduce, tetapi alih-alih hanya satu proses yang mendapatkan hasilnya, semua proses dalam komunikator menerima salinan dari hasil akhir. Ini berguna ketika semua proses memerlukan hasil agregasi untuk melanjutkan komputasi berikutnya.
Distribusi Data: MPI_Bcast (Broadcast)
MPI_Bcast adalah kebalikan dari MPI_Reduce. Fungsi ini mengambil data dari satu proses sumber dan mengirimkan salinannya ke semua proses lain dalam komunikator. Ini adalah cara yang jauh lebih efisien untuk mendistribusikan input daripada menggunakan loop MPI_Send seperti pada catatan sebelumnya.
int MPI_Bcast(void* data_p, int count, MPI_Datatype datatype, int source_proc, MPI_Comm comm);
data_p: Pada source_proc, ini adalah data yang akan dikirim. Pada proses lain, ini adalah buffer untuk menerima data.
source_proc: Rank dari proses yang menjadi sumber data.
Aturan Penting Komunikasi Kolektif
Wajib Partisipasi: Semua proses dalam komunikator HARUS memanggil fungsi kolektif yang sama. Jika ada satu proses yang tidak memanggil atau memanggil fungsi yang berbeda, program akan mengalami deadlock.
Argumen Harus Kompatibel: Argumen kunci seperti count, datatype, operator, dan dest/source process harus sama di semua proses.
Tidak Menggunakan Tag: Komunikasi kolektif tidak menggunakan tag. Pencocokan operasi didasarkan pada urutan pemanggilan fungsi di dalam komunikator.
Summary
Komunikasi kolektif adalah mekanisme sinkronisasi di mana semua proses dalam sebuah komunikator berpartisipasi dalam operasi data global, yang secara signifikan lebih efisien daripada komunikasi point-to-point berulang. Fungsi-fungsi kunci seperti MPI_Reduce digunakan untuk agregasi data ke satu proses, MPI_Allreduce untuk agregasi ke semua proses, dan MPI_Bcast untuk distribusi data dari satu ke semua proses, dengan aturan ketat bahwa semua proses harus memanggil fungsi yang sama dengan argumen yang kompatibel.
Additional Information
Efisiensi Komunikasi: Tree vs. Linear
Mari kita analisis kompleksitas waktunya. Misalkan ada p proses.
Agregasi Linear (dengan loop Send/Recv): Proses 0 harus melakukan (p-1) kali Recv. Waktu totalnya sebanding dengan (p-1). Ini tidak scalable.
Agregasi Pohon (digunakan oleh MPI_Reduce): Jumlah langkah komunikasi sebanding dengan tinggi pohon, yaitu log(p). Ini jauh lebih efisien dan scalable untuk jumlah proses yang besar. Inilah kekuatan sesungguhnya dari komunikasi kolektif.
Variasi Fungsi Kolektif
MPI menyediakan banyak sekali varian fungsi kolektif untuk berbagai pola komunikasi. Sebagai contoh, ada MPI_Scan, yang melakukan “prefix reduction”. Misalnya, jika data inputnya adalah [1, 2, 3, 4] dan operasinya adalah MPI_SUM, maka proses 0 akan mendapat 1, proses 1 mendapat 1+2=3, proses 2 mendapat 1+2+3=6, dan proses 3 mendapat 1+2+3+4=10. Ini berguna dalam algoritma paralel tertentu.
Eksplorasi Mandiri
Refactor Kode Aturan Trapesium: Ubah kode dari Catatan 2. Ganti loop MPI_Send/MPI_Recv untuk distribusi input dengan satu panggilan MPI_Bcast. Kemudian, ganti loop MPI_Send/MPI_Recv untuk agregasi hasil dengan satu panggilan MPI_Reduce. Bandingkan kebersihan dan potensi kecepatan kode yang baru.
Mengukur Kinerja: Coba ukur waktu eksekusi dari kedua versi program (loop vs. kolektif) dengan jumlah proses yang semakin banyak. Anda seharusnya melihat bahwa versi kolektif memiliki skalabilitas yang lebih baik.
Sumber & Referensi Lanjutan:
Topik Pencarian: “MPI collective communication algorithms”, “Binomial tree broadcast algorithm”, “MPI_Reduce vs MPI_Allreduce performance”.
Visualisasi: Cari visualisasi online tentang cara kerja algoritma broadcast dan reduce untuk mendapatkan pemahaman intuitif yang lebih baik.