Perkembangan hardware paralel (seperti multicore) tidak akan memberikan peningkatan performa jika software tidak dirancang untuk memanfaatkannya. Kompiler modern belum cukup pintar untuk mengubah program serial menjadi program paralel yang efisien secara otomatis. Oleh karena itu, beban untuk mengekspos dan mengelola paralelisme sepenuhnya berada di tangan programmer.
Model Pemrograman Paralel Utama
Ada dua pendekatan fundamental untuk menulis program paralel, yang sangat dipengaruhi oleh arsitektur hardware yang mendasarinya.
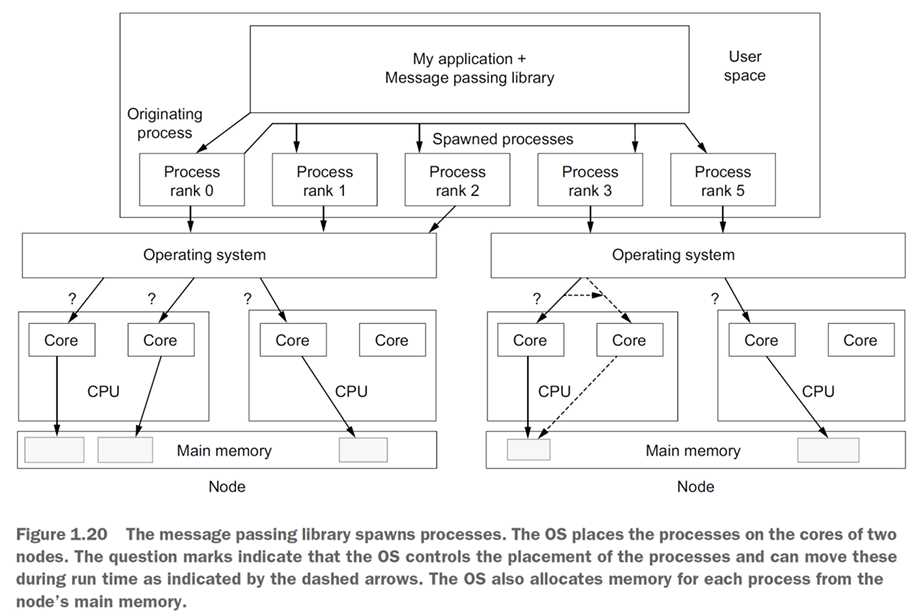
Process-based (Message Passing):
Konsep: Program utama meluncurkan beberapa proses independen. Setiap proses memiliki ruang memori privatnya sendiri.
Komunikasi: Karena memori terisolasi, proses-proses ini berkomunikasi dengan cara saling mengirim dan menerima pesan secara eksplisit.
Cocok untuk: Arsitektur Distributed Memory.
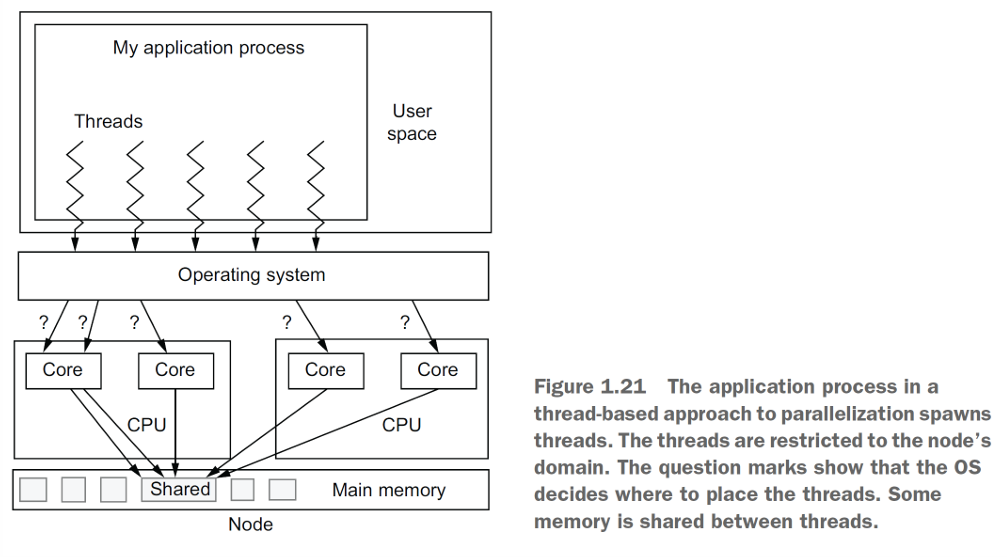
Thread-based (Shared Data):
Konsep: Program utama berjalan sebagai satu proses, yang kemudian membuat beberapa threads. Semua thread ini berjalan di dalam proses yang sama dan berbagi ruang memori yang sama.
Komunikasi:Threads berkomunikasi secara implisit dengan cara membaca dan menulis ke variabel yang sama di memori bersama.
Cocok untuk: Arsitektur Shared Memory.
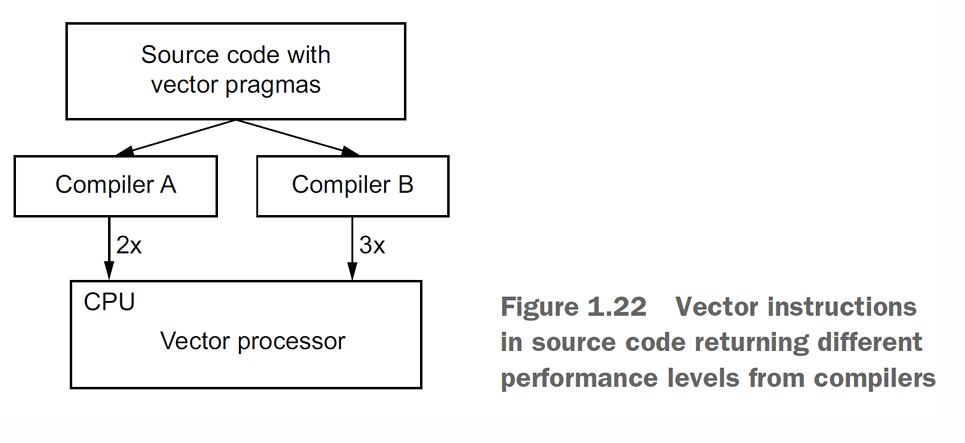
Vectorization (SIMD)
Konsep: Memanfaatkan unit hardware khusus (seperti Vector Processor di CPU) untuk menjalankan satu instruksi pada banyak data sekaligus.
Implementasi: Programmer sering kali memberikan petunjuk (pragmas) kepada kompiler, dan kompiler akan mencoba menghasilkan instruksi vektor yang efisien.
Catatan: Performanya bergantung dengan compiler yang digunakan.
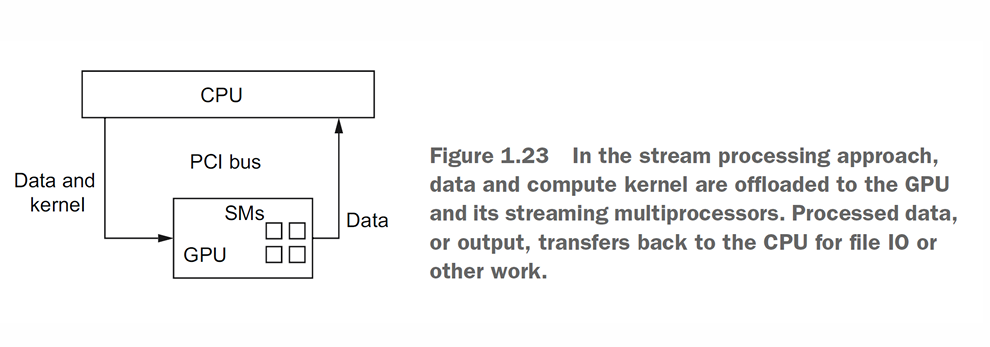
Stream Processing
Konsep: Sebuah pola yang spesifik untuk hardware akselerator seperti GPU. CPU akan “memindahkan” (offload) data dan fungsi komputasi (kernel) ke GPU.
Alur Kerja: Ribuan core di GPU akan memproses aliran (stream) data tersebut secara masif dan paralel. Setelah selesai, hasilnya dikirim kembali ke CPU.
SPMD (Single Program, Multiple Data)
Ini adalah gaya pemrograman yang sangat umum dalam komputasi paralel. Idenya adalah kita hanya menulis satu kode program, yang kemudian akan dieksekusi oleh semua proses atau thread. Namun, setiap proses/thread bisa berperilaku berbeda dengan menggunakan percabangan kondisional berdasarkan identitas unik mereka (disebut rank atau ID).
// Contoh SPMDif (my_rank == 0) { // Lakukan tugas master} else { // Lakukan tugas worker}
Tantangan dalam Pemrograman Paralel
Langkah-langkah:
Bagi pekerjaan di antara proses/thread
(a) sehingga setiap proses/thread mendapatkan jumlah pekerjaan yang kurang lebih sama
(b) dan komunikasi diminimalkan.
Atur agar proses/thread melakukan sinkronisasi.
Atur komunikasi di antara proses/thread
Penggunaan thread dalam Shared Memory dapat dibagi dalam dua jenis:
Thread Dinamis
Thread master menunggu pekerjaan, membuat (forks) thread baru, dan ketika thread selesai, mereka berhenti (terminate).
Penggunaan sumber daya yang efisien, tetapi pembuatan dan penghentian thread memakan waktu.
Thread Statis
Sekumpulan (pool) thread dibuat dan dialokasikan pekerjaan, tetapi tidak berhenti sampai proses pembersihan (cleanup).
Performa lebih baik, tetapi berpotensi membuang-buang sumber daya sistem.
Namun, menulis program paralel mengenalkan beberapa tantangan unik yang tidak ada dalam pemrograman serial.
Nondeterminism: Karena setiap thread berjalan dengan kecepatannya sendiri, urutan eksekusi antar thread tidak dapat diprediksi. Jika beberapa thread mencoba mencetak ke layar, urutan outputnya bisa berbeda setiap kali program dijalankan.
Race Condition: Masalah serius yang terjadi ketika beberapa thread mencoba mengakses (membaca dan menulis) lokasi memori yang sama secara bersamaan, dan hasil akhirnya bergantung pada urutan eksekusi yang tidak menentu tersebut.
Contoh: Dua thread mencoba menambahkan nilainya ke variabel global x. Thread 0 membaca x (nilai 0), lalu Thread 1 membaca x (masih 0), kemudian Thread 0 menulis hasilnya (0+7=7), dan terakhir Thread 1 menulis hasilnya (0+19=19). Nilai x akhir menjadi 19, padahal seharusnya 26.
Solusi: Mutual Exclusion (Mutex): Untuk mencegah race condition, bagian kode yang mengakses data bersama (disebut critical section) harus dilindungi. Hanya satu thread yang diizinkan masuk ke critical section pada satu waktu. Ini dicapai dengan menggunakan lock atau mutex.
Solusi Lain: Busy Waiting: Salah satu solusi lain yang dapat dipertimbangkan adalah busy waiting. Ia memaksa sebuah thread untuk menunggu secara aktif (terus-menerus memeriksa sebuah kondisi dalam loop) sampai thread lain memberikan sinyal bahwa ia boleh melanjutkan.
Dengan cara ini, kita memaksakan sebuah urutan eksekusi yang deterministik pada bagian kode yang kritis. Thread B tidak akan pernah bisa mendahului thread A dalam mengakses data bersama, sehingga race condition dapat dihindari. Jadi, ia “menyembuhkan” gejala (race condition) yang disebabkan oleh sifat dasar (nondeterminism).
Kelemahan utama busy-waiting adalah sangat tidak efisien. Thread yang sedang menunggu akan menghabiskan 100% siklus CPU-nya hanya untuk berputar dalam loop kosong. Ini sama saja dengan membakar energi dan sumber daya komputasi tanpa melakukan pekerjaan yang produktif.
my_val = Compute_val(my_rank); if ( my_rank == 1) while ( ! ok_for_1 ) ; /* Busy−wait loop */x += my_val ; /* Critical section */if ( my_rank == 0) ok_for_1 = true ; /* Let thread 1 update x */
Komunikasi dan Manajemen I/O
Message Passing: Dalam model distributed memory, proses berkomunikasi dengan perintah Send dan Receive. Satu proses mengirim pesan, dan proses lain harus siap menerimanya.
Input/Output (I/O):
Input (stdin): Biasanya, hanya satu proses/thread (misalnya, rank 0) yang diizinkan membaca dari input standar untuk menghindari kekacauan.
Output (stdout): Semua proses/thread bisa menulis ke output, tetapi karena nondeterminism, urutannya tidak akan terjamin. Oleh karena itu, untuk output final, biasanya hanya satu proses/thread yang melakukannya, sementara yang lain digunakan untuk debugging (dengan menyertakan rank/ID).
File I/O: Aturan umumnya adalah tidak boleh ada dua proses/thread yang membuka dan menulis ke file yang sama secara bersamaan. Setiap proses/thread bisa mengelola filenya sendiri.
Summary
Pemrograman paralel menuntut programmer untuk secara eksplisit mengelola paralelisme, umumnya menggunakan model thread-based untuk shared memory atau process-based (message passing) untuk distributed memory. Gaya pemrograman SPMD memungkinkan satu basis kode untuk dijalankan oleh banyak entitas paralel yang dibedakan oleh ID unik mereka. Namun, pendekatan ini menimbulkan tantangan seperti nondeterminism dan race condition, yang harus diatasi dengan mekanisme sinkronisasi seperti mutex untuk melindungi critical section dan memastikan kebenaran program.
Additional Information
Pendalaman Teknis: Static vs. Dynamic Threads
Dalam model thread-based, ada dua cara mengelola thread:
Static Threads: Sebuah pool (kumpulan) thread dibuat saat program dimulai dan tetap aktif menunggu pekerjaan. Mereka baru berhenti saat program selesai. Ini lebih efisien karena tidak ada overhead pembuatan thread berulang kali, tetapi bisa memboroskan sumber daya jika thread lebih banyak diam.
Dynamic Threads:Thread master hanya akan membuat thread baru saat ada pekerjaan yang perlu dilakukan. Setelah selesai, thread tersebut akan dihancurkan. Ini lebih hemat sumber daya tetapi memiliki overhead yang signifikan dari proses pembuatan dan penghancuran thread yang terus-menerus.
Analogi Sederhana: Race Condition di Dapur
Bayangkan Anda dan teman Anda (threads) sedang membuat kue dan ada satu toples gula (shared memory). Resepnya bilang “tambahkan 1 cangkir gula”.
Anda membaca resep (read).
Teman Anda juga membaca resep (read).
Anda mengambil 1 cangkir gula (compute & write).
Teman Anda juga mengambil 1 cangkir gula (compute & write).
Hasilnya, kue menjadi terlalu manis karena ada 2 cangkir gula, padahal seharusnya hanya 1.
Solusi Mutex: Letakkan “gembok” (lock) di toples gula. Siapa pun yang mau mengambil gula harus mengambil gemboknya dulu. Selama Anda memegang gembok, teman Anda harus menunggu. Setelah Anda selesai dan mengembalikan gembok, baru teman Anda bisa mengambilnya. Ini memastikan hanya satu orang yang mengakses toples gula pada satu waktu.
Eksplorasi Mandiri
Cari tahu tentang OpenMP: Selain Pthreads dan MPI, OpenMP adalah model pemrograman paralel populer untuk shared memory. Ciri khasnya adalah penggunaan directive atau #pragma di dalam kode C/C++/Fortran. Cari contoh sederhana “Hello World” menggunakan OpenMP dan bandingkan betapa mudahnya dibandingkan dengan membuat thread secara manual.