Back to IF3140 Sistem Basis Data
Sistem Paralel: Konsep & Metrik Kinerja
Questions/Cues
Apa itu Parallel Database System?
Apa beda Coarse-grain vs Fine-grain?
Apa 2 metrik kinerja utama?
Apa itu Throughput?
Apa itu Response Time?
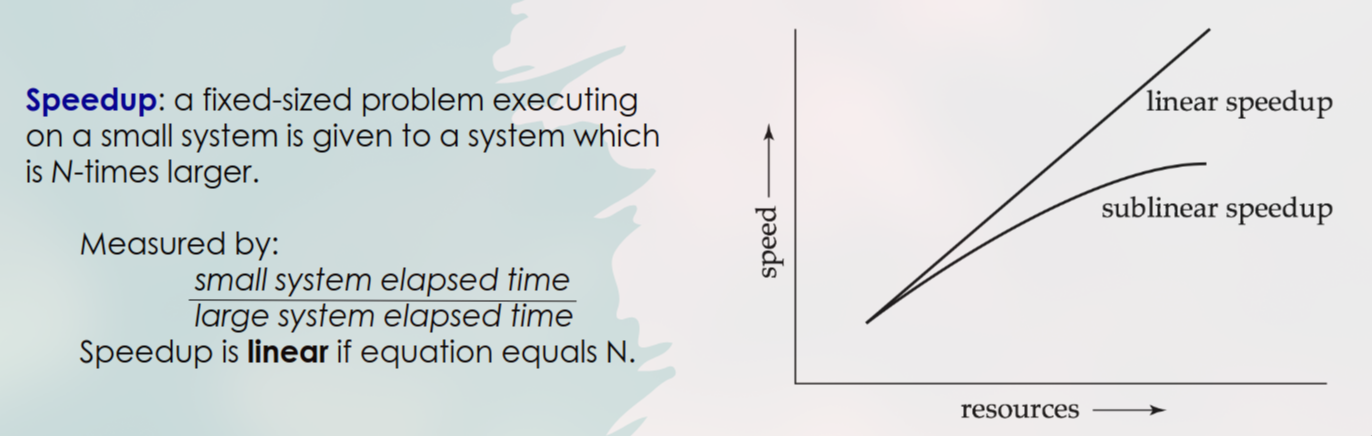
Apa itu Speedup?
Apa arti Linear Speedup?
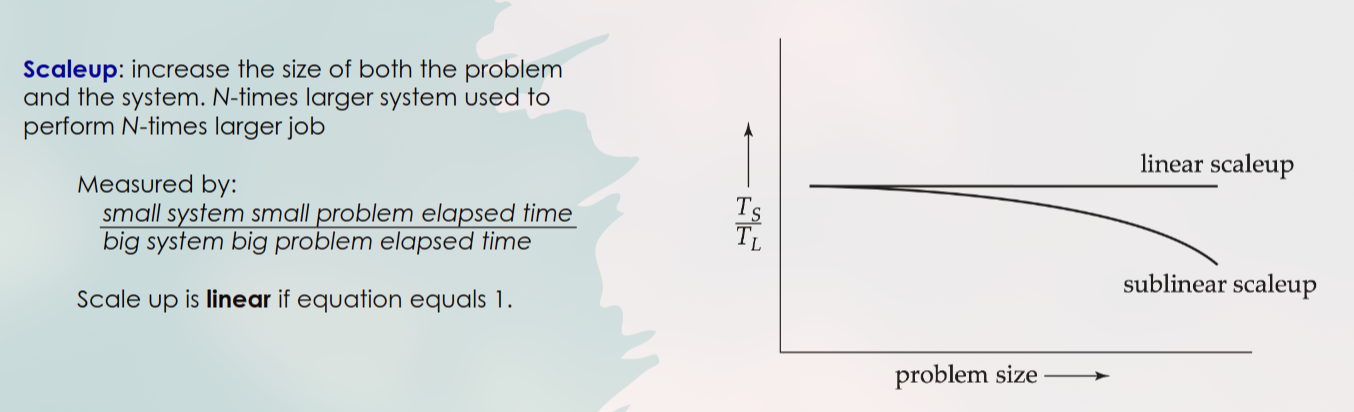
Apa itu Scaleup?
Apa arti Linear Scaleup?
Apa beda Batch Scaleup vs Transaction Scaleup?
Apa 3 faktor penghambat Speedup & Scaleup?
Apa itu Startup Costs?
Apa itu Interference?
Apa itu Skew?
Reference Points
- Slides “13 - Database System Architectures.pdf” (Slide 22-26)
1. Parallel Database Systems
Sistem Database Paralel adalah sistem yang menggunakan banyak processor dan banyak disk yang terhubung oleh jaringan interkoneksi berkecepatan tinggi, untuk menjalankan tugas database secara bersamaan (paralel).
Coarse-grain: Sistem dengan sedikit (misal: 4-64) processor yang powerful.
Fine-grain / Massively Parallel: Sistem dengan ribuan processor yang lebih “lemah”.
Tujuannya adalah untuk meningkatkan performa. Ada dua cara mengukur performa:
Throughput: Jumlah tugas (transaksi) yang dapat diselesaikan dalam satu interval waktu. (Ukuran: tasks per second).
Response Time: Waktu yang dibutuhkan untuk menyelesaikan satu tugas, dari saat dikirim hingga selesai. (Ukuran: seconds).
2. Metrik Kinerja: Speedup
Speedup mengukur seberapa cepat sistem yang lebih besar bisa menyelesaikan pekerjaan dengan ukuran masalah yang tetap.
Rumus:
Waktu di sistem kecil / Waktu di sistem N-kali lebih besarLinear Speedup: Peningkatan performa yang ideal. Jika kita menambah hardware 2x lipat (misal: 4 CPU jadi 8 CPU), pekerjaan selesai 2x lebih cepat. (Hasil = N).
Sublinear Speedup: Peningkatan performa di dunia nyata. Menambah hardware 2x lipat hanya mempercepat 1.8x, karena ada overhead.
3. Metrik Kinerja: Scaleup
Scaleup mengukur kemampuan sistem untuk menangani pekerjaan yang lebih besar dengan memberinya hardware yang lebih besar.
Rumus:
Waktu (masalah kecil di sistem kecil) / Waktu (masalah N-kali lebih besar di sistem N-kali lebih besar)Linear Scaleup: Peningkatan yang ideal. Jika kita menambah hardware 2x lipat (4 jadi 8 CPU) dan juga menambah ukuran data 2x lipat, waktu eksekusi tetap sama. (Hasil = 1).
Sublinear Scaleup: Kinerja di dunia nyata. Saat hardware dan data ditambah 2x lipat, waktu eksekusi malah jadi lebih lambat (misal: 1.1x).
Jenis Scaleup:
Batch Scaleup: Untuk 1 pekerjaan besar (misal: query data warehouse). Data 1TB di 16 CPU vs Data 10TB di 160 CPU.
Transaction Scaleup: Untuk banyak pekerjaan kecil (misal: OLTP/e-commerce). 1000 user di 16 CPU vs 10.000 user di 160 CPU.
4. Faktor Penghambat (Limitasi)
Speedup dan scaleup jarang sekali linear (ideal) karena 3 alasan:
Startup Costs (Biaya Awal)
- Biaya untuk memulai (inisialisasi) ribuan proses paralel di banyak CPU.
- Jika tugasnya sangat singkat, waktu untuk memulai proses bisa lebih lama daripada waktu eksekusi tugas itu sendiri.
Interference (Interferensi / Bottleneck)
Proses-proses paralel saling “berebut” sumber daya yang digunakan bersama (shared resource).
Contoh: berebut bus memori, berebut lock di lock table, berebut I/O disk. Proses akhirnya lebih banyak menunggu daripada bekerja.
Skew (Kemiringan / Ketidakseimbangan)
- Pembagian kerja yang tidak merata di antara processor.
- Waktu eksekusi total ditentukan oleh processor yang kerjanya paling lambat (paling banyak).
- Contoh: Memproses data pelanggan. Processor A kebagian 1000 pelanggan dari Jakarta, Processor B kebagian 10 pelanggan dari Papua. Processor B selesai duluan dan menganggur, sementara semua menunggu Processor A selesai.
Sistem Paralel menggunakan banyak CPU dan disk untuk meningkatkan performa, yang diukur dengan Throughput (tugas per detik) dan Response Time (detik per tugas). Kinerja idealnya diukur dengan Speedup (menyelesaikan masalah tetap lebih cepat di sistem besar) dan Scaleup (menyelesaikan masalah besar di sistem besar dalam waktu tetap). Kinerja linear (ideal) jarang tercapai di dunia nyata karena adanya tiga penghambat: Startup Costs (biaya inisialisasi proses), Interference (perebutan bottleneck), dan Skew (pembagian kerja yang tidak seimbang).
Additional Information
Pendalaman Teknis: Skew dalam Praktik
Skew adalah musuh terbesar dalam database paralel. Bayangkan query
GROUP BY kota.
Sistem mempartisi data berdasarkan
hash(kota).Kebetulan
hash('Jakarta'),hash('Surabaya'), danhash('Bandung')semua berakhir di Node 1.Sementara
hash('Medan')di Node 2,hash('Makassar')di Node 3, dst.Node 1 akan kebanjiran data (data skew) dan bekerja sangat keras, sementara Node 2 dan 3 selesai dengan cepat dan menganggur.
Waktu total query = waktu yang dihabiskan Node 1.
Ini disebut Partition Skew. Ada juga Execution Skew di mana datanya terbagi rata, tapi satu query (misal: join yang kompleks) kebetulan jauh lebih berat daripada query lainnya.
Pendalaman Teknis: Hukum Amdahl
Sublinear Speedup (Slide 23) dijelaskan secara formal oleh Hukum Amdahl.
Hukum Amdahl menyatakan bahwa speedup sebuah program dibatasi oleh bagian program yang tidak bisa diparalelkan (bagian serial).
Misal: Sebuah query 10% serial (membaca disk, mengumpulkan hasil akhir) dan 90% paralel (memproses data).
Bahkan jika Anda memberi tak terhingga jumlah processor, bagian 90% akan selesai dalam 0 detik, tapi Anda akan selalu terjebak di bagian 10% yang serial.
Ini berarti speedup maksimumnya adalah
1 / 0.10 = 10x, tidak peduli seberapa banyak hardware yang Anda tambahkan.Inilah mengapa interference (perebutan resource yang serial) sangat membatasi speedup.
Sumber & Referensi Lanjutan:
Buku: Silberschatz, Korth, Sudarshan, “Database System Concepts”, 7th Ed, Chapter 20.3.
Konsep: “Amdahl’s Law”, “Data Skew in Parallel Databases”.