Back to IF3140 Sistem Basis Data
Topic
Questions/Cues
Apa saja algoritma join utama?
Bagaimana cara kerja Nested-Loop Join?
Apa itu Block Nested-Loop Join?
Kapan Indexed Nested-Loop Join efisien?
Bagaimana prinsip Merge-Join?
Apa itu Hash-Join?
Fase Partisi vs. Build/Probe di Hash-Join?
Bagaimana menangani overflow pada Hash-Join?
Apa itu Hybrid Hash-Join?
Cara menangani join kompleks (AND/OR)?
Reference Points
- Slides 26-44
Nested-Loop Join
Ini adalah algoritma join yang paling dasar dan sederhana.
Cara Kerja: Untuk setiap tuple di relasi luar (r), pindai seluruh relasi dalam (s) untuk mencari pasangan yang memenuhi kondisi join.
Kelebihan: Dapat digunakan untuk semua jenis kondisi join (tidak hanya kesetaraan) dan tidak memerlukan indeks.
Kekurangan: Sangat tidak efisien dan mahal.
Estimasi Biaya (Worst Case): blok seek time, di mana adalah jumlah record di relasi r dan adalah jumlah blok di relasi s.
Best Case: Jika relasi luar sangat kecil.
Worst Case: Jika dan sama-sama besar.
Block Nested-Loop Join
Merupakan variasi dari Nested-Loop Join yang bekerja pada level blok, bukan tuple.
Cara Kerja: Untuk setiap blok di relasi luar (r), pindai seluruh blok di relasi dalam (s). Kemudian, untuk setiap pasang blok, semua kombinasi tuple di dalamnya akan diperiksa.
Estimasi Biaya (Worst Case):
Optimasi: Alokasikan blok memori untuk relasi luar, sehingga dapat membaca blok sekaligus dan mengurangi jumlah pemindaian relasi dalam. Biaya menjadi .
Best Case: Jika relasi luar yang dipilih sangat kecil, sehingga muat dalam memori yang tersedia ().
Worst Case: Jika dan sama-sama besar.
Indexed Nested-Loop Join
Algoritma ini memanfaatkan indeks pada atribut join dari relasi dalam untuk mempercepat pencarian.
Syarat: Kondisi join harus berupa equi-join (atau natural join) dan harus ada indeks pada atribut join relasi dalam.
Cara Kerja: Untuk setiap tuple di relasi luar (r), gunakan indeks pada relasi dalam (s) untuk langsung menemukan tuple yang cocok, tanpa perlu memindai seluruh relasi s.
Estimasi Biaya: , di mana
cadalah biaya untuk mencari dan mengambil semua tuple yang cocok disuntuk satu tuplermenggunakan indeks.Best Case: Jika relasi luar sangat kecil DAN indeks yang dipilih sangat selektif pada atribut join di relasi dalam .
Worst Case: Jika indeks relasi dalam TIDAK selektif.
Merge-Join
Algoritma ini efisien untuk equi-joins dan natural joins.
Cara Kerja:
Sort: Urutkan kedua relasi (r dan s) berdasarkan atribut join mereka.
Merge: Pindai kedua relasi yang sudah terurut secara bersamaan (mirip fase merge pada External Sort-Merge) untuk menemukan tuple yang cocok. Pointer akan bergerak maju secara sinkron di kedua relasi.
Estimasi Biaya (jika relasi sudah terurut): transfer blok, karena setiap blok hanya perlu dibaca sekali. Jika belum terurut, biaya sorting harus ditambahkan.
Best Case: Jika relasi luar dan relasi dalam sudah terurut.
Worst Case: Jika dan tidak terurut.
Secara umum:
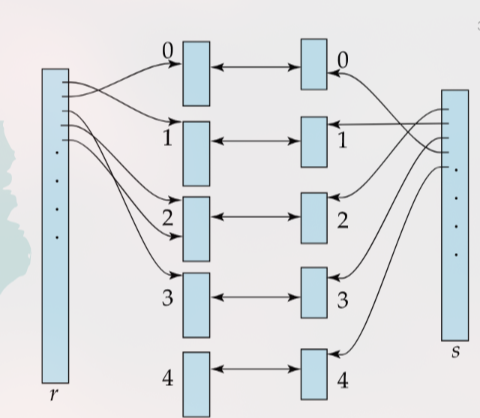
Hash-Join
Ini adalah algoritma yang sangat efisien untuk equi-joins, terutama pada data besar.
Cara Kerja:
Fase Partisi (Partition Phase):
Pilih relasi yang lebih kecil sebagai build input (misalnya s).
Gunakan fungsi hash
h1pada atribut join untuk mempartisisdanrke dalamnbucket atau partisi ( dan ).Tulis partisi-partisi ini ke disk. Keuntungannya adalah tuple di hanya mungkin cocok dengan tuple di .
Fase Build & Probe (Matching Phase):
- Untuk setiap partisi i:
Build: Baca partisi ke memori dan bangun hash table di memori menggunakan fungsi hash kedua ().
Probe: Baca partisi blok per blok, dan untuk setiap tuple, gunakan h2 untuk mencari pasangannya di hash table .
Penanganan Overflow: Jika partisi tidak muat di memori, partisi tersebut dapat dipartisi ulang secara rekursif menggunakan fungsi hash lain, atau gunakan Block Nested-Loop Join untuk partisi yang meluap tersebut.
Estimasi Biaya (tanpa rekursi): Sekitar
Best Case: Paling baik untuk operasi equi-join pada data besar dengan memori yang cukup, dan ketika fungsi hash mampu mendistribusikan kunci join secara merata ke semua partisi. Distribusi yang merata memastikan tidak ada partisi yang “meluap” (overflow) dan setiap partisi dari relasi build () bisa dimuat ke memori saat fase probe. Varian Hybrid Hash-Join memberikan optimasi lebih lanjut dalam skenario ini.
Worst Case: Ketika terjadi kemiringan data (data skew) yang signifikan pada atribut join. Ini berarti banyak sekali record memiliki nilai atribut join yang sama. Akibatnya, fungsi hash akan menempatkan semua record tersebut ke dalam satu partisi yang sama.
Hybrid Hash-Join
Sebuah optimasi dari Hash-Join ketika memori cukup besar.
Cara Kerja: Selama fase partisi build input (s), partisi pertama () tidak ditulis ke disk, melainkan langsung disimpan di memori sebagai hash table. Ketika probe input (r) dipartisi, tuple yang masuk ke partisi tidak ditulis ke disk, melainkan langsung digunakan untuk mencari pasangan di hash table . Ini menghemat I/O untuk satu partisi penuh.
Complex Joins
Join dengan Kondisi Konjungtif (AND):
- Hitung join untuk kondisi yang paling selektif (misalnya ), lalu terapkan kondisi sisanya () sebagai filter pada hasilnya.
Join dengan Kondisi Disjungtif (OR):
Hitung hasil join untuk setiap kondisi secara terpisah (
dan).Gabungkan hasilnya menggunakan operasi
UNION.
Pemilihan algoritma join adalah salah satu keputusan paling kritis dalam optimasi query, dengan setiap algoritma memiliki kelebihan pada skenario yang berbeda. Nested-Loop Join adalah metode universal tetapi lambat. Block Nested-Loop Join memberikan perbaikan sederhana. Indexed Nested-Loop Join sangat cepat jika tersedia indeks yang sesuai. Merge-Join efisien untuk equi-join pada data yang sudah atau dapat diurutkan dengan mudah. Terakhir, Hash-Join seringkali menjadi pilihan tercepat untuk equi-join pada data besar, dengan varian Hybrid Hash-Join yang lebih lanjut mengoptimalkan penggunaan memori untuk mengurangi I/O disk.
Additional Information
Tabel Perbandingan Algoritma Join
Algoritma Kapan Digunakan Terbaik Persyaratan Kelemahan Nested-Loop Relasi sangat kecil atau sebagai fallback Tidak ada Sangat lambat untuk data besar Block Nested-Loop Salah satu relasi kecil, memori terbatas Tidak ada Kurang efisien dibanding hash/merge Indexed Nested-Loop Relasi luar kecil, ada indeks efisien di relasi dalam Indeks pada atribut join Performa buruk jika indeks tidak selektif Merge-Join Kedua relasi sudah terurut atau output perlu diurutkan Equi-join, data terurut Biaya sorting awal bisa mahal Hash-Join Equi-join pada data besar, memori cukup Equi-join Sensitif terhadap data miring (skew) dan ukuran memori Dampak Data Skew (Kemiringan Data) pada Hash-Join
Kelemahan utama Hash-Join adalah jika data pada atribut join tidak terdistribusi merata (miring). Misalnya, jika banyak sekali tuple memiliki nilai yang sama pada atribut join, maka fungsi hash akan menempatkan semua tuple tersebut ke dalam satu partisi yang sama. Partisi ini akan menjadi sangat besar dan menyebabkan overflow, yang akan memaksa sistem menggunakan algoritma yang lebih lambat seperti Block Nested-Loop Join pada partisi tersebut, sehingga mengurangi efisiensi keseluruhan.
Eksplorasi Mandiri
Gunakan perintah
EXPLAINatauEXPLAIN ANALYZEpada DBMS favorit Anda untuk melihat bagaimana query optimizer memilih algoritma join.
Buat dua tabel,
AdanB.Lakukan
JOINtanpa membuat indeks apa pun. Kemungkinan besar optimizer akan memilih Hash Join atau Merge Join.Buat indeks B-Tree pada kolom join di tabel
B.Jalankan kembali query
JOIN. Jika tabelAcukup kecil, optimizer mungkin akan beralih ke Indexed Nested-Loop Join denganAsebagai relasi luar danBsebagai relasi dalam. Ini menunjukkan bagaimana optimizer secara dinamis memilih strategi terbaik berdasarkan struktur data yang tersedia.