Back to IF3140 Sistem Basis Data
Topic
Questions/Cues
Kapan sorting diperlukan?
Apa saja metode sorting untuk data besar?
Apa itu External Sort-Merge?
Tahap 1: Create Sorted Runs?
Tahap 2: Merge the Runs?
Bagaimana jika jumlah run lebih besar dari memori (N ≥ M)?
Analisis Biaya: Block Transfers?
Analisis Biaya: Seeks?
Reference Points
- Slides 19-25
Kebutuhan dan Metode Sorting
Sorting (pengurutan) adalah operasi fundamental yang sering dibutuhkan dalam database, misalnya untuk klausa
ORDER BY, beberapa implementasiJOIN,GROUP BY, dan eliminasi duplikat.Metode Implementasi
Menggunakan Indeks: Jika ada indeks pada atribut yang ingin diurutkan, sistem dapat membaca pointer dari leaf node indeks secara berurutan untuk mengambil data. Namun, metode ini bisa menjadi sangat mahal karena setiap tuple bisa berada di blok disk yang berbeda, menyebabkan satu I/O per tuple.
In-Memory Sorting: Jika seluruh relasi muat di dalam memori, algoritma sorting standar seperti Quicksort dapat digunakan dengan sangat efisien.
External Sort-Merge: Ini adalah algoritma pilihan ketika data relasi terlalu besar untuk muat di dalam memori.
External Sort-Merge
Algoritma ini bekerja dalam dua fase utama untuk mengurutkan data yang lebih besar dari RAM. Anggap M adalah ukuran memori yang tersedia (dalam jumlah blok/halaman).
Fase 1: Membuat Run Terurut (Create Sorted Runs)
Baca M blok dari relasi ke dalam memori.
Urutkan M blok tersebut di dalam memori (misalnya, menggunakan Quicksort).
Tulis kembali hasil yang sudah terurut ke disk sebagai satu file sementara yang disebut “run”.
Ulangi langkah 1-3 sampai semua blok dari relasi telah diproses, menghasilkan sejumlah N runs yang masing-masing sudah terurut secara internal.
Fase 2: Menggabungkan Run (Merge the Runs)
Setelah semua run terbentuk, fase ini menggabungkannya menjadi satu output akhir yang terurut.
N-Way Merge: Jika jumlah run (N) lebih kecil dari memori (M), penggabungan dapat dilakukan dalam satu kali jalan.
Alokasikan 1 blok memori sebagai buffer input untuk setiap run (total N blok).
Alokasikan 1 blok memori sebagai buffer output.
Secara berulang, ambil record terkecil dari semua buffer input, pindahkan ke buffer output.
Jika buffer output penuh, tulis ke disk. Jika buffer input kosong, isi kembali dari run yang bersangkutan di disk.
Penanganan Jika N ≥ M
Jika jumlah run lebih banyak dari blok memori yang tersedia, proses merge tidak bisa dilakukan sekali jalan. Diperlukan beberapa kali pass penggabungan (merge passes).
Pada setiap pass, gabungkan sekelompok (M-1) runs menjadi satu run baru yang lebih panjang.
Proses ini akan mengurangi jumlah run dengan faktor (M-1) pada setiap pass.
Ulangi proses ini sampai semua run berhasil digabung menjadi satu.
Analisis Biaya External Sort-Merge
Analisis biaya berfokus pada dua komponen utama: jumlah transfer blok dan jumlah seeks.
Biaya Transfer Blok
Setiap pass (baik itu pass pembuatan run awal maupun pass penggabungan) akan membaca seluruh
$b_r$blok dan menuliskan kembali seluruh$b_r$blok.
Total transfer blok untuk keseluruhan proses (dengan asumsi output akhir tidak dihitung biaya tulisnya) dirumuskan sebagai:
$b_r$: Jumlah blok relasi.
M: Ukuran memori dalam blok.
$b_b$: Jumlah blok buffer yang dialokasikan per run saat merging.
$\lceil log_{...} \rceil$: Menghitung jumlah merge pass yang dibutuhkan.Biaya Seeks
Seek terjadi setiap kali sistem perlu membaca atau menulis sekumpulan blok baru yang tidak berdekatan.
Saat pembuatan run: Membutuhkan
$2 * \lceil b_r / M \rceil$seeks (satu untuk membaca, satu untuk menulis setiap potongan berukuran M).Saat merging: Jumlah seeks tergantung pada berapa banyak blok yang dibaca/ditulis sekaligus (
$b_b$).Total seeks dirumuskan sebagai:
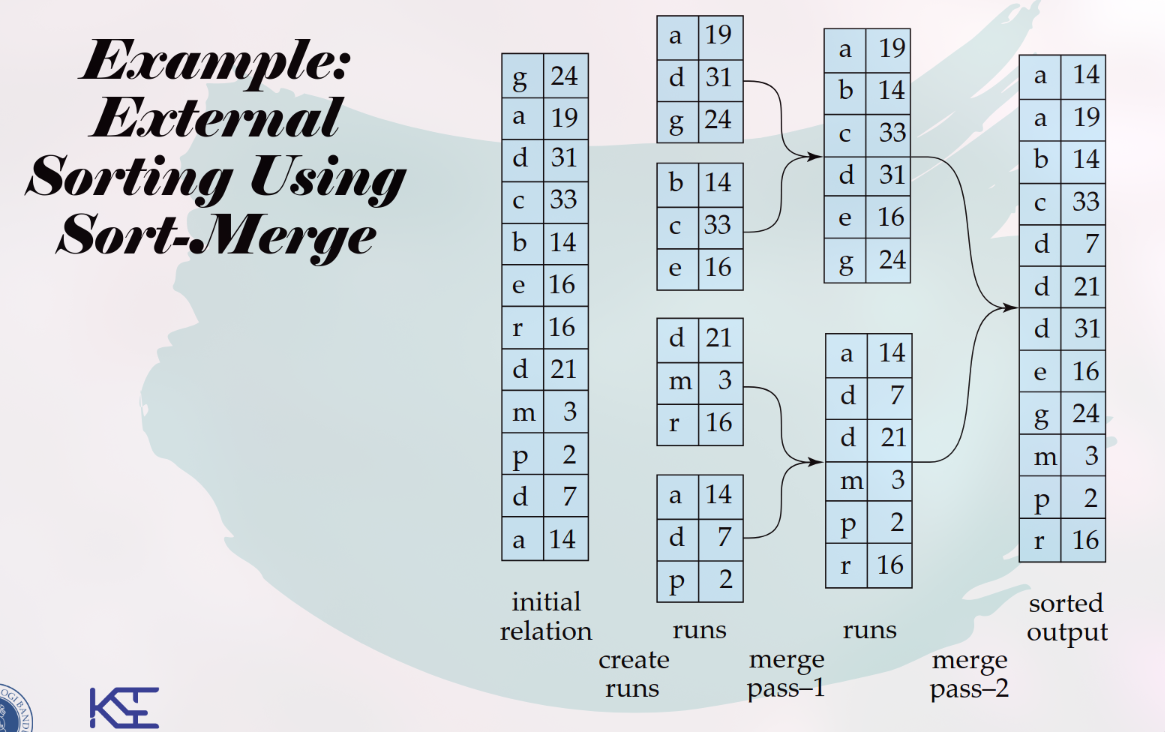
External Sort-Merge adalah algoritma standar untuk mengurutkan relasi yang ukurannya melebihi memori utama, yang bekerja dalam dua fase: membuat sejumlah run terurut dan kemudian menggabungkan run-run tersebut. Jika jumlah run melebihi kapasitas memori, penggabungan dilakukan dalam beberapa pass. Biaya totalnya, yang diukur dalam transfer blok dan seeks, sangat bergantung pada ukuran memori (M) karena ini menentukan berapa banyak pass penggabungan yang diperlukan untuk menyelesaikan seluruh proses.
Additional Information
Peran
$b_b$: Buffer Blocks per RunVariabel
$b_b$(jumlah blok buffer per run saat merge) adalah parameter penting untuk optimasi.
Jika
$b_b = 1$, maka setiap kali buffer input habis, sistem harus melakukan seek baru untuk membaca satu blok berikutnya. Ini menghasilkan banyak sekali seeks.Dengan menaikkan nilai
$b_b$(misalnya menjadi 10), sistem dapat membaca 10 blok sekaligus dalam satu operasi I/O, sehingga jumlah seek total pada fase merge berkurang drastis, meskipun ini mengurangi jumlah run yang bisa digabung dalam satu pass ($\lfloor M/b_b\rfloor-1$). Query optimizer akan mencoba mencari nilai$b_b$yang optimal.Contoh Perhitungan Biaya Sederhana
Relasi
rmemiliki$b_r = 1000$blok.Memori
M = 101blok.Kita alokasikan
$b_b = 1$blok per buffer.
Pembuatan Run:
Jumlah run yang dibuat:
$\lceil 1000 / 101 \rceil = 10$runs.Biaya: Baca 1000 blok + Tulis 1000 blok = 2000 transfer blok.
Penggabungan Run:
Jumlah run (10) < Ukuran memori (101), jadi cukup 1 merge pass.
Kita bisa menggabungkan hingga
M-1 = 100runs sekaligus.Biaya: Baca 1000 blok (dari 10 runs) + Tulis 1000 blok (output akhir).
Total Biaya (dengan biaya tulis akhir):
2000 (fase 1) + 2000 (fase 2) = 4000 transfer blok.
Jika menggunakan rumus dari slide (tanpa biaya tulis akhir):
Jumlah merge pass:
$\lceil log_{100}(1000/101) \rceil = \lceil log_{100}(9.9) \rceil = 1$.Total transfer:
$1000 * (2*1 + 1) = 3000$blok. (Baca+Tulis di fase 1, dan Baca di fase 2).Eksplorasi Mandiri
Perhatikan bahwa jika memori
Msangat besar, mendekati$b_r$, maka$\lceil b_r/M \rceil$akan menjadi 1. Artinya, hanya ada satu run yang dibuat, dan tidak ada fase merge yang diperlukan. Algoritma ini secara alami beradaptasi menjadi in-memory sort.Sebaliknya, jika memori
Msangat kecil (misalM=2), maka akan dibuat$b_r/2$runs dan jumlah merge pass akan sangat banyak, membuat biayanya melambung tinggi.