Back to IF3140 Sistem Basis Data
Topic
Questions/Cues
Apa itu indeks dan apa dua jenis dasarnya?
Apa perbedaan Primary dan Secondary Index?
Apa perbedaan Dense dan Sparse Index?
Apa kelemahan dari Indeks Terurut sederhana?
Konsep Dasar Indexing
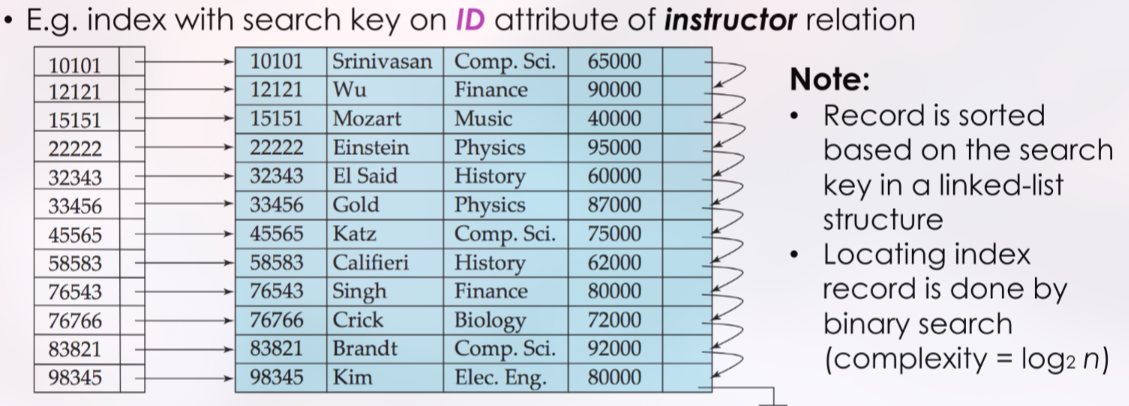
Indeks adalah sebuah struktur data yang digunakan untuk mempercepat akses ke data yang diinginkan, mirip seperti katalog di perpustakaan. Setiap entri indeks terdiri dari search-key (nilai dari kolom yang diindeks) dan pointer (penunjuk ke lokasi record data).
File Indeks biasanya lebih kecil ukurannya dibandingkan file utamanya.
Secara fundamental, ada dua jenis indeks: Indeks Terurut (Ordered Index), di mana entri disimpan secara terurut, dan Indeks Hash (Hash Index), di mana entri disebar ke dalam “bucket” menggunakan fungsi hash.
Parameter/Metrik Evaluasi Indeks
- Tipe Akses yang Didukung (Access Types): Seberapa efisien sebuah indeks mendukung berbagai jenis kueri atau cara mengakses data. Dua tipe akses yang paling umum adalah:
Pencarian Nilai Spesifik (Point Query): Mencari record berdasarkan nilai atribut yang tepat. Contoh:
SELECT * FROM mahasiswa WHERE nim = '12345';Pencarian Rentang Nilai (Range Query): Mencari record yang nilai atributnya berada dalam rentang tertentu. Contoh:
SELECT * FROM produk WHERE harga BETWEEN 10000 AND 50000;Sebuah indeks yang baik harus bisa menangani kedua tipe akses ini dengan cepat.
Waktu Akses (Access Time): Waktu yang dibutuhkan untuk menemukan data atau record tertentu menggunakan indeks.
Waktu Penyisipan (Insertion Time): Waktu yang dibutuhkan untuk menyisipkan (insert) record baru ke dalam tabel dan sekaligus memperbarui struktur indeksnya. Indeks yang kompleks mungkin memerlukan waktu lebih lama untuk penyisipan karena harus menjaga keterurutan dan struktur internalnya.
Waktu Penghapusan (Deletion Time) : Waktu yang dibutuhkan untuk menghapus record dari tabel dan juga dari struktur indeks. Sama seperti penyisipan, proses ini juga melibatkan pembaruan pada indeks.
Overhead Ruang (Space Overhead) : Ini adalah ruang penyimpanan tambahan yang dibutuhkan oleh file indeks itu sendiri. Setiap indeks yang kita buat akan memakan ruang di disk. Metrik ini mengukur seberapa besar “biaya” ruang yang harus dikeluarkan untuk mendapatkan keuntungan kinerja dari indeks tersebut. Idealnya, kita menginginkan overhead ruang yang sekecil mungkin.
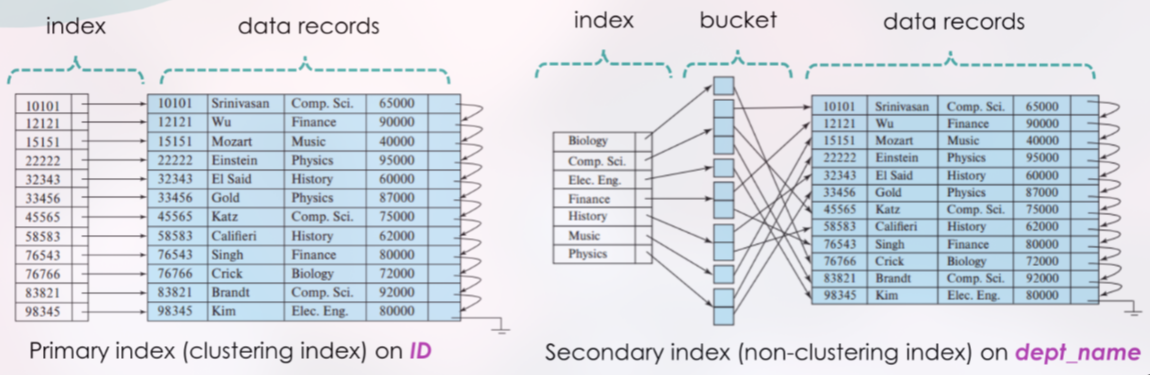
Primary vs. Secondary Index
Primary Index (Clustering Index): Sebuah indeks di mana search key-nya menentukan urutan fisik dari record di dalam file. Karena record hanya bisa diurutkan secara fisik dalam satu cara, sebuah tabel hanya bisa memiliki satu primary/clustering index.
Secondary Index (Non-Clustering Index): Sebuah indeks di mana urutan search key-nya berbeda dari urutan fisik record di dalam file. Sebuah tabel bisa memiliki banyak secondary index.
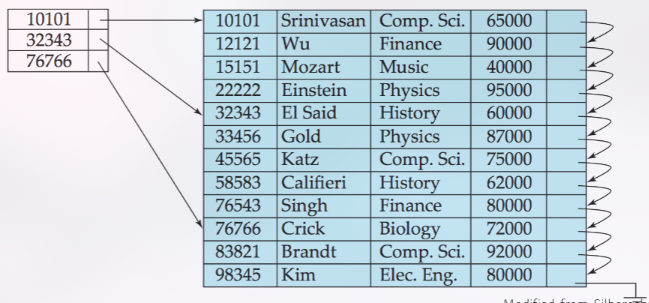
Dense vs. Sparse Index
Dense Index: Berisi entri untuk setiap nilai search-key yang ada di dalam file data. Secondary Index harus selalu bersifat dense.
Sparse Index: Hanya berisi entri untuk beberapa nilai search-key (misalnya, entri untuk setiap blok data). Ini hanya bisa diterapkan pada file yang sudah terurut berdasarkan search key yang sama (yaitu pada primary index). Sparse index lebih hemat ruang tetapi umumnya lebih lambat untuk pencarian dibandingkan dense index.
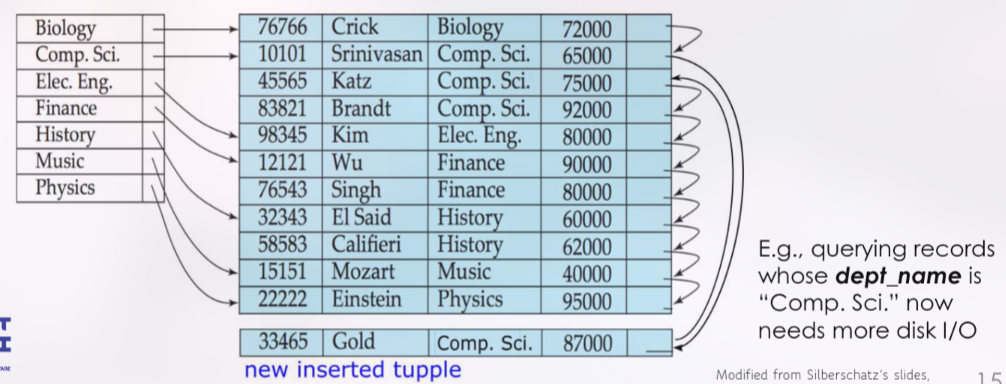
Masalah Utama Ordered Indices: Overflow Blocks
- Efek Operasi Data: Ketika data baru ditambahkan (
Insert), dihapus (Delete), atau diubah (Update), file akan terus bertambah besar. Masalahnya, data harus tetap terurut. Jika sebuah blok data sudah penuh dan ada data baru yang seharusnya masuk ke blok tersebut, data baru itu akan ditempatkan di area khusus yang disebut overflow block.
- Contoh pada Gambar:
Terdapat indeks untuk
dept_name(Biology, Comp. Sci., dst.) yang menunjuk ke record data pertama untuk setiap departemen.Sebuah data baru (
new inserted tupple) untuk departemen “Comp. Sci.” dengan nama “Gold” ditambahkan.Karena blok data untuk “Comp. Sci.” kemungkinan sudah penuh, record baru ini dimasukkan ke dalam overflow block. Pointer dari blok utama kemudian akan menunjuk ke blok tambahan ini.
Konsekuensi: Penurunan Kinerja
Peningkatan Random Disk I/O: Semakin banyak overflow block yang dibuat, semakin banyak pula operasi baca/tulis disk secara acak (random disk I/O) yang dibutuhkan.
Mengapa Ini Terjadi? Saat kita mencari data (misalnya, semua mahasiswa di “Comp. Sci.”), sistem database tidak lagi bisa membaca data secara sekuensial (berurutan) yang cepat. Sebaliknya, ia harus:
Membaca blok data utama.
Mengikuti pointer untuk “melompat” ke overflow block.
Jika ada lebih banyak overflow block, ia harus melompat lagi.
Proses “lompat-lompat” antar blok di disk ini jauh lebih lambat daripada membaca satu blok data yang berurutan, sehingga kinerja kueri menurun.
Solusi: Reorganisasi Periodik
Tujuan: Untuk mengatasi penurunan kinerja, diperlukan reorganisasi file secara berkala (periodic reorganization).
Proses: Reorganisasi pada dasarnya adalah proses membangun kembali file data dan indeksnya. Semua data dari overflow block akan diintegrasikan kembali ke dalam struktur file utama sesuai urutannya.
Hasil: Setelah reorganisasi, semua overflow block akan hilang, dan akses data kembali menjadi efisien dan sekuensial. Kinerja kueri pun kembali optimal.
Multilevel Index dan Kelemahannya
Jika sebuah indeks (terutama sparse index) menjadi terlalu besar untuk dimuat ke memori, kita bisa membuat indeks dari indeks tersebut, yang disebut Multilevel Index. Namun, kelemahan mendasar dari semua struktur indeks terurut sederhana (index-sequential file) adalah kinerjanya akan menurun seiring dengan banyaknya operasi insert dan delete. Hal ini menciptakan banyak blok luapan (overflow blocks) yang mengacaukan urutan dan memperlambat akses, sehingga memerlukan reorganisasi file secara berkala yang memakan biaya.
Indeks berfungsi mempercepat pencarian data dengan menyimpan pasangan search-key dan pointer. Indeks Terurut menyimpan entri secara terurut dan dibedakan menjadi Primary (Clustering) yang urutannya sama dengan data fisik, dan Secondary (Non-Clustering) yang urutannya berbeda. Indeks juga bisa bersifat Dense (semua key ada) atau Sparse (hanya beberapa key). Kelemahan utama dari struktur ini adalah degradasi performa karena overflow blocks saat data berubah, yang menjadi motivasi untuk struktur yang lebih dinamis seperti B+-Tree.
Additional Information (Optional)
Analogi Buku Telepon
Primary Index: Bayangkan buku telepon di mana nama orang (data) sudah diurutkan secara alfabetis. Urutan buku itu sendiri adalah indeksnya. Anda hanya bisa punya satu urutan utama.
Secondary Index: Sekarang, bayangkan di halaman belakang buku telepon ada daftar tambahan yang diurutkan berdasarkan alamat jalan. Daftar ini (indeks) menunjuk ke halaman di mana nama orang tersebut berada. Urutan berdasarkan alamat ini berbeda dengan urutan utama berdasarkan nama.
Sparse Index: Alih-alih menulis setiap nama di tepi halaman, Anda hanya menulis nama pertama untuk setiap halaman (misal: “A”, “B”, “C”). Untuk mencari “Anderson”, Anda pergi ke halaman “A” lalu mencari secara sekuensial dari sana.
Dense Index: Setiap nama di buku telepon ditulis di tepi halaman. Ini tidak praktis untuk buku fisik, tetapi menggambarkan cara kerja dense index pada file data yang tidak terurut.