Back to IF3170 Inteligensi Artifisial
Topic: Naive Bayes Classifier (Supervised Learning)
Questions/Cues
Apa itu Naive Bayes?
Mengapa disebut “Naive”?
Rumus Prediksi Utama
Tahap Learning
Tahap Classification
Contoh Kasus (Tennis)
Reference Points
File:
28. IF3170_Materi09_Seg02_AI-NaiveBayes.pdfModul: Supervised Learning
1. Konsep Dasar Naive Bayes
Naive Bayes adalah Probabilistic Classifier dalam Supervised Learning.
Target Fungsi: Memetakan input ke kelas dari himpunan terbatas .
Prinsip: Menggunakan Teorema Bayes untuk memprediksi kelas yang paling mungkin () berdasarkan atribut yang diamati.
Asumsi “Naive”: Mengasumsikan bahwa setiap atribut bersifat saling lepas (conditionally independent) satu sama lain jika kelasnya diketahui. Meskipun asumsi ini jarang terjadi di dunia nyata, performa Naive Bayes seringkali sangat baik.
2. Algoritma Pembelajaran (Learning Algorithm)
Tujuan tahap ini adalah membangun “Probability Model” dari data latih.
Input: Dataset dengan atribut dan target kelas .
Proses:
Hitung frekuensi setiap kelas target .
Hitung frekuensi setiap nilai atribut untuk setiap kelas .
3. Tahap Klasifikasi (Prediction)
Untuk data baru (unseen data) dengan atribut , kita mencari kelas (Maximum a Posteriori) dengan rumus:
Menggunakan Teorema Bayes dan asumsi independensi, rumusnya disederhanakan menjadi:
: Prior probability (peluang kelas muncul secara umum).
: Likelihood (peluang atribut muncul jika kelasnya , dikalikan untuk semua atribut).
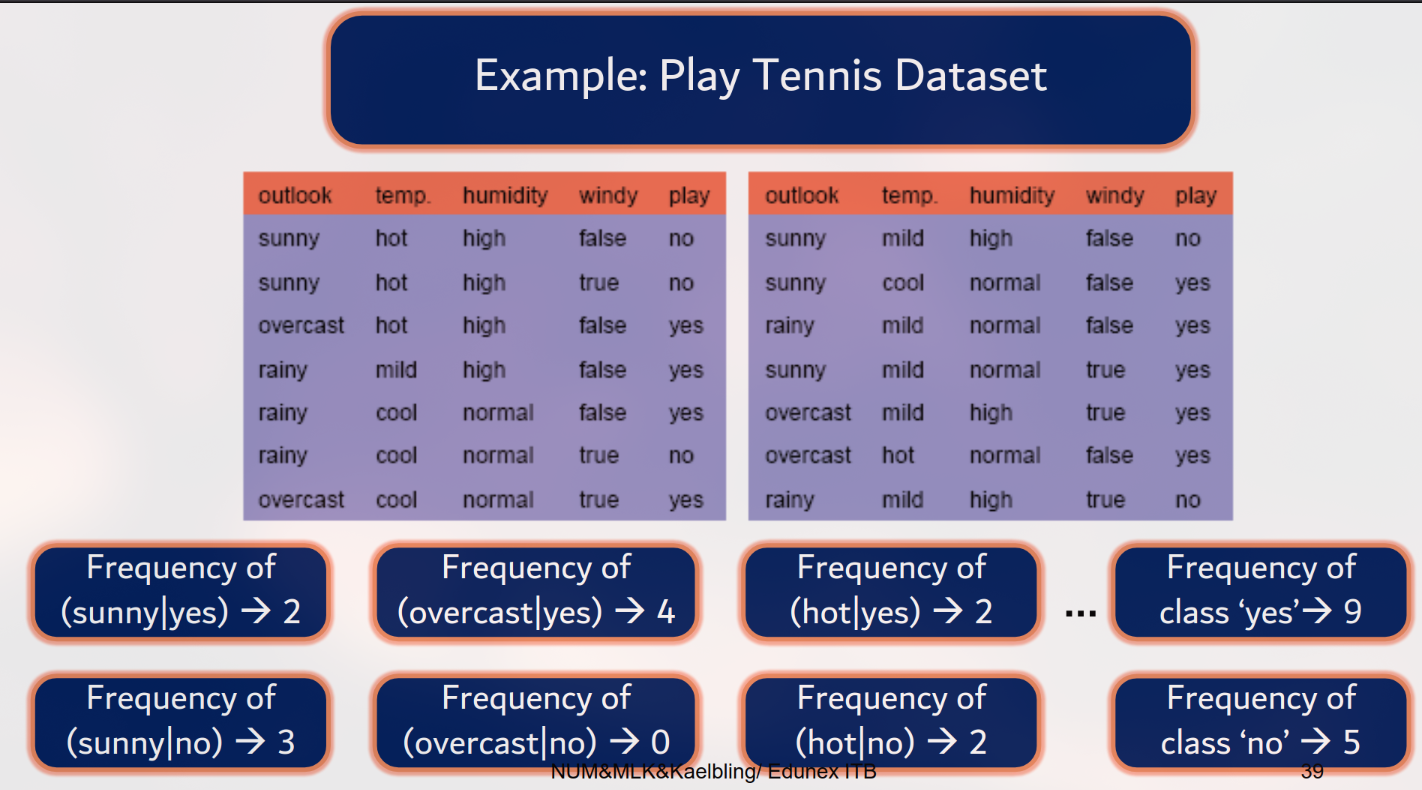
4. Studi Kasus: Play Tennis
Diberikan data cuaca (Outlook, Temp, Humidity, Windy) untuk menentukan Play=Yes/No.
Learning: Hitung tabel probabilitas.
, .
, , dst.
Query: ?
Hitung Yes:
Hitung No:
Keputusan: , maka prediksi Play = No.

Naive Bayes adalah pengklasifikasi probabilistik yang efisien yang memprediksi kelas dengan memilih probabilitas tertinggi (). Kekuatan utamanya terletak pada asumsi independensi atribut yang menyederhanakan perhitungan kompleks menjadi perkalian probabilitas sederhana berdasarkan frekuensi data latih.
Spaced Repetition Questions
1. Mengapa Naive Bayes disebut "Naive"?
Karena algoritma ini mengasumsikan bahwa semua atribut input bersifat independen satu sama lain (tidak saling mempengaruhi) jika kelas targetnya diketahui, padahal kenyataannya atribut seringkali berkorelasi.
2. Apa rumus utama untuk mengklasifikasikan data baru menggunakan Naive Bayes?
(Peluang Prior Kelas dikali dengan Produk Peluang Likelihood setiap atribut).