Back to IF3170 Inteligensi Artifisial
Topic: SVM for Linearly Separable Data (Mathematics & Optimization)
Questions/Cues
Definisi Matematis Support Vector
Persamaan Bidang Pembatas
Rumus Lebar Margin
Fungsi Objektif SVM
Quadratic Programming (QP)
Primal vs Dual Problem
Peran Lagrange Multiplier (Alpha)
Cara menghitung bias (b)
Reference Points
Slides: 17-38
Modul: Supervised Learning
1. Definisi Formal Support Vector & Margin
Pada data yang linearly separable (dapat dipisahkan sempurna secara linear), SVM mencari dua bidang pembatas paralel yang memisahkan data dengan jarak terjauh.
Persamaan Bidang:
Hyperplane Tengah (Pemisah):
Pembatas Kelas +1: (Data di garis ini labelnya +1)
Pembatas Kelas -1: (Data di garis ini labelnya -1)
Kondisi Matematis:
Agar klasifikasi benar dan berada di luar margin, seluruh data latih harus memenuhi pertidaksamaan:
Jika hasilnya , maka data tersebut berada tepat di garis pembatas. Data inilah yang disebut Support Vector.
Jika hasilnya , maka data berada di zona aman (bukan support vector).
2. Optimasi Margin (Objective Function)
Tujuan SVM adalah memaksimalkan lebar margin ().
Rumus Lebar Margin:
Jarak tegak lurus antara pembatas kelas +1 dan -1 adalah:
Masalah Optimasi: Untuk memaksimalkan margin, kita harus meminimalkan .
Secara matematis, untuk memudahkan penurunan rumus (agar bisa diturunkan/derivative), kita meminimalkan kuadratnya:
Primal Problem (Masalah Asli):
Subject to: (Semua data harus benar di luar margin).
Ini adalah masalah Convex Quadratic Programming (QP).
3. Lagrange Multipliers & Dual Problem
Masalah optimasi di atas (Primal) sulit diselesaikan langsung karena ada kendala pertidaksamaan. Kita mengubahnya menjadi masalah Dual menggunakan metode Lagrange Multipliers.
Transformasi ke Dual Problem:
Kita memperkenalkan variabel baru bernama Alpha () untuk setiap titik data.
Fungsi Dual yang Harus Dimaksimalkan:
Kendala Baru:
Keuntungan Bentuk Dual:
Masalah kini hanya bergantung pada Dot Product antar data latih. Ini sangat krusial untuk menangani data non-linear nanti (menggunakan Kernel Trick).
4. Interpretasi Nilai Alpha ()
Setelah masalah optimasi diselesaikan (biasanya menggunakan software QP Solver), kita mendapatkan nilai untuk setiap data.
Jika : Data tersebut bukan Support Vector. Data ini tidak berpengaruh pada pembentukan garis pemisah.
Jika : Data tersebut adalah Support Vector. Data ini terletak tepat di batas margin ().
5. Menghitung Model Akhir ( dan )
Setelah nilai ditemukan:
Hitung Bobot ():
(Hanya support vector yang berkontribusi karena lainnya 0).
Hitung Bias ():
Ambil salah satu support vector (), lalu masukkan ke persamaan:
(Dalam prakteknya, sering dirata-rata dari semua support vector untuk kestabilan numerik).
Fungsi Klasifikasi Baru:
6. Studi Kasus Perhitungan Manual (Step-by-Step)
Dataset 2D Sederhana:
Kita punya 3 data latih.
Kelas Positif (+1): ,
Kelas Negatif (-1):
Analisis Visual: paling dekat dengan , kemungkinan besar mereka adalah Support Vector. ada di belakang .
Langkah 1: Hitung Dot Product ()
Rumus:
Perkalian Pasangan Data Perhitungan Hasil 18 21 6 25 7 2 Langkah 2: Menyusun Persamaan Dual
Kendala: .
Asumsi: jauh di belakang, jadi bukan support vector. Set .
Maka: .
Masukkan ke Fungsi :
L = (\alpha_1 + \alpha_3) - \frac{1}{2} [ \alpha_1^2 y_1 y_1 (x_1 \cdot x_1) + \alpha_3^2 y_3 y_3 (x_3 \cdot x_3) + 2 \alpha_1 \alpha_3 y_1 y_3 (x_1 \cdot x_3) ]$$$$L = 2\alpha - \frac{1}{2} [ \alpha^2(1)(18) + \alpha^2(1)(2) + 2(\alpha)(\alpha)(-1)(6) ]$$$$L = 2\alpha - \frac{1}{2} [ 18\alpha^2 + 2\alpha^2 - 12\alpha^2 ]$$$$L = 2\alpha - \frac{1}{2} [ 8\alpha^2 ] = 2\alpha - 4\alpha^2
Langkah 3: Cari Alpha Optimal
Turunkan terhadap dan samakan dengan 0:
(Support Vector)
(Support Vector)
(Bukan)
Langkah 4: Hitung Bobot ()
Langkah 5: Hitung Bias ()
Gunakan salah satu Support Vector (misal ).
Langkah 6: Persamaan Akhir & Verifikasi
Fungsi Keputusan:
Uji Data Perhitungan Hasil Target Status 1 +1 Support Vector 1.5 +1 Benar (>1) -1 -1 Support Vector 7. Studi Kasus 2 (PPT)
Dataset
x1 x2 Kelas 3 1 +1 3 -1 +1 6 1 +1 6 -1 +1 1 0 -1 0 1 -1 0 -1 -1 -1 0 -1
Identifikasi Support Vectors
Dari visualisasi data, titik-titik yang paling dekat antar kelas (yang berada di perbatasan) adalah:
Support Vectors yang dipilih:
- SV1: (1, 0) dengan kelas -1
- SV2: (3, 1) dengan kelas +1
- SV3: (3, -1) dengan kelas +1
Titik-titik ini ditandai dengan lingkaran kuning pada plot.
Langkah 1: Menyusun Persamaan dari Syarat Support Vector
Untuk Support Vector, berlaku:
Kita akan menyusun persamaan untuk ketiga support vector:
Persamaan 1: Titik (1, 0) → Kelas -1
Persamaan 2: Titik (3, 1) → Kelas +1
Persamaan 3: Titik (3, -1) → Kelas +1
Persamaan 4: Constraint SVM
Langkah 2: Penyelesaian Sistem Persamaan Linear
Sistem persamaan yang harus diselesaikan:
Eliminasi (2) dan (3):
Substitusi (5) ke (1) dan (2):
Dari (1):
Dari (2):
Eliminasi (6) dan (7):
Substitusi (5) dan (8) ke constraint (4):
Cari variabel lainnya:
Substitusi ke (6) untuk mencari b:
Hasil Akhir
Fungsi Hipotesis:
dengan:
- α₁ = 0.5
- α₂ = α₃ = 0.25
Langkah 3: Pengujian Hipotesis
Uji dengan data baru: x = (6, 1)
Hitung dot products:
Substitusi:
Hasil: Data (6, 1) diprediksi masuk kelas +1 ✓
Visualisasi Hasil
Hyperplane yang terbentuk memisahkan:
- Kelas -1 (kotak merah) di sebelah kiri
- Kelas +1 (titik biru) di sebelah kanan
Support Vectors (lingkaran kuning):
- (1, 0) dengan α₁ = 0.5
- (3, 1) dengan α₂ = 0.25
- (3, -1) dengan α₃ = 0.25
Garis hitam vertikal adalah hyperplane pemisah dengan persamaan yang didapat dari model SVM.
8. Studi Kasus 3: Perhitungan Kompleks (3 Support Vectors)
Dataset:
Data x1 x2 Kelas (y) 3 1 +1 3 -1 +1 6 1 +1 6 -1 +1 1 0 -1 0 1 -1 0 -1 -1 -1 0 -1 Identifikasi Support Vectors:
Secara visual, data yang paling berdekatan antar kelas adalah:
Kelas -1: Titik terluar kanan . (Kita sebut ini data ke-1 untuk perhitungan, )
Kelas +1: Titik terluar kiri dan . (Kita sebut ini data ke-2 dan ke-3, ).
Langkah 1: Menyusun Persamaan dari Syarat SV
Untuk Support Vector, berlaku .
Rumus: .
Kita akan menyusun persamaan berdasarkan 3 titik yang diduga SV:
Titik 1 (Kelas -1):
Titik 2 (Kelas +1):
(Note: , )
Titik 3 (Kelas +1):
Constraint SVM ():
Langkah 2: Penyelesaian Sistem Persamaan Linear
Eliminasi (2) dan (3):
Substitusi (5) ke (1) dan (2):
(1) menjadi:
(2) menjadi:
Eliminasi (6) dan (7):
(6) - (7)
Substitusi (5) dan (8) ke Constraint (4):
Cari variabel lain:
Substitusi ke (6):
Hasil Akhir Model:
.
Karena semua , ketiga titik tersebut benar merupakan Support Vectors.
Langkah 3: Pengujian Hipotesis
Misal ada data baru . Prediksi kelasnya?
Sign(4) = +1. (Data masuk kelas Positif).
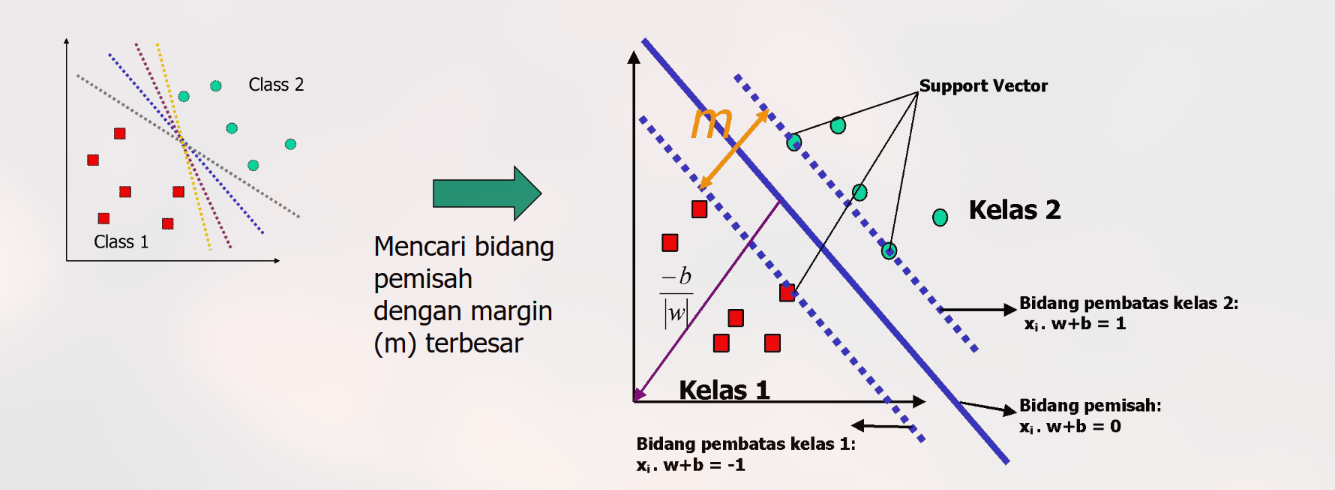
Pada data Linearly Separable, SVM diformulasikan sebagai masalah Quadratic Programming (QP) dengan tujuan meminimalkan (yang ekuivalen dengan memaksimalkan margin ) dengan kendala klasifikasi yang benar. Masalah ini diselesaikan menggunakan metode Lagrange Multipliers dalam bentuk Dual Problem, di mana kita mencari nilai . Hanya data dengan yang menjadi Support Vectors dan menentukan bentuk hyperplane akhir.
Ad Libitum: Derivasi & Kalkulasi Detail
1. Mengapa Lebar Margin = ?
Misalkan kita punya dua hyperplane paralel:
Ambil sembarang titik di dan di . Jarak antara kedua bidang adalah proyeksi vektor pada vektor normal satuan .
w \cdot x_1 = 1 - b$$$$w \cdot x_2 = -1 - b
Kurangi persamaan:
Bagi kedua sisi dengan :
Sisi kiri adalah definisi jarak proyeksi. Maka terbukti lebar margin adalah .
2. Contoh Perhitungan Manual (Sederhana)
Misal ada 3 titik 1D (Sesuai slide 33-36 tapi disederhanakan):
Kelas +1:
Kelas -1:
Support vector pasti di dan .
Jaraknya 2 unit. Margin optimal harus di tengah ().
Setengah lebar margin = 1.
Maka .
Cek Bias:
(untuk kelas +1, )
.
Fungsi keputusan: .
Cek (Kelas +1). Cek (Kelas +1? Salah, harusnya -1).
Jika kelas kiri +1 dan kanan -1, maka harus negatif.
Perhitungan SVM yang benar akan otomatis menangani tanda +/- ini melalui optimasi .
Spaced Repetition Questions (Review)
Cobalah menjawab pertanyaan berikut untuk menguji pemahaman teknis Anda.
1. Apa hubungan antara meminimalkan ||w|| dengan margin?
Lebar margin didefinisikan sebagai . Oleh karena itu, untuk memaksimalkan margin (membuat jalan pemisah selebar mungkin), kita harus meminimalkan penyebutnya, yaitu norma vektor bobot .
2. Dalam solusi Dual Problem, apa arti jika sebuah data memiliki alpha = 0?
Jika , berarti data tersebut bukan Support Vector. Data ini berada jauh dari batas margin (di zona aman) dan tidak memiliki pengaruh apapun terhadap pembentukan garis keputusan (hyperplane).
3. Mengapa kita lebih memilih menyelesaikan SVM dalam bentuk Dual Problem daripada Primal Problem?
Karena dalam bentuk Dual, fungsi objektifnya hanya bergantung pada Dot Product antar data . Hal ini memungkinkan penggunaan Kernel Trick nantinya untuk menangani data yang tidak terpisah secara linear (non-linear).
4. Bagaimana persamaan kendala (constraint) SVM dituliskan secara matematis?
Artinya, untuk semua data latih, hasil proyeksi dan bias harus setidaknya bernilai 1 (untuk kelas positif) atau setidaknya -1 (untuk kelas negatif, dikali jadi positif), yang menjamin data berada di luar margin.
5. Berapa banyak data yang biasanya memiliki alpha > 0 pada dataset yang besar?
Biasanya hanya sebagian kecil dari total data (sparse). Hanya titik-titik yang paling sulit diklasifikasikan (di perbatasan) yang memiliki \alpha > 0. Inilah yang membuat SVM efisien dalam memori untuk menyimpan model akhirnya.