Back to IF3170 Inteligensi Artifisial
Topic
Questions/Cues
Apa masalah di pabrik pengemasan ikan?
Bagaimana dataset dibangun dari gambar?
Apa itu ekstraksi fitur?
Mengapa fitur ‘panjang’ saja tidak cukup?
Mengapa fitur ‘kecerahan’ lebih baik?
Apa itu decision boundary?
Apa itu overfitting?
Apa itu generalisasi?
Reference Points
- IF3170-Materi-08-Seg-02 - Learning - Supervised.pdf (Slide 5-15)
Latar Belakang Masalah
Sebuah pabrik pengemasan ikan ingin mengotomatisasi proses penyortiran ikan di conveyor belt. Sistem perlu dapat membedakan antara dua spesies: Salmon dan Sea Bass. Ini adalah masalah klasifikasi biner.
Pembangunan Dataset & Ekstraksi Fitur
Pengambilan Gambar: Kamera CCD mengambil gambar setiap ikan yang lewat.
Pra-pemrosesan (Preprocessing): Gambar mentah diproses melalui beberapa tahap:
Enhancement: Kualitas gambar ditingkatkan.
Segmentasi: Objek ikan dipisahkan dari latar belakangnya.
Resize: Ukuran gambar diseragamkan.
Ekstraksi Fitur (Feature Extraction): Alih-alih menggunakan piksel mentah, kita mengekstrak karakteristik fisik yang dapat diukur (fitur) yang diharapkan dapat membedakan kedua spesies. Contoh fitur:
Panjang (Length)
Kecerahan (Lightness)
Lebar (Width)
Bentuk sirip, posisi mulut, dll.
Analisis Fitur & Pemodelan Iteratif
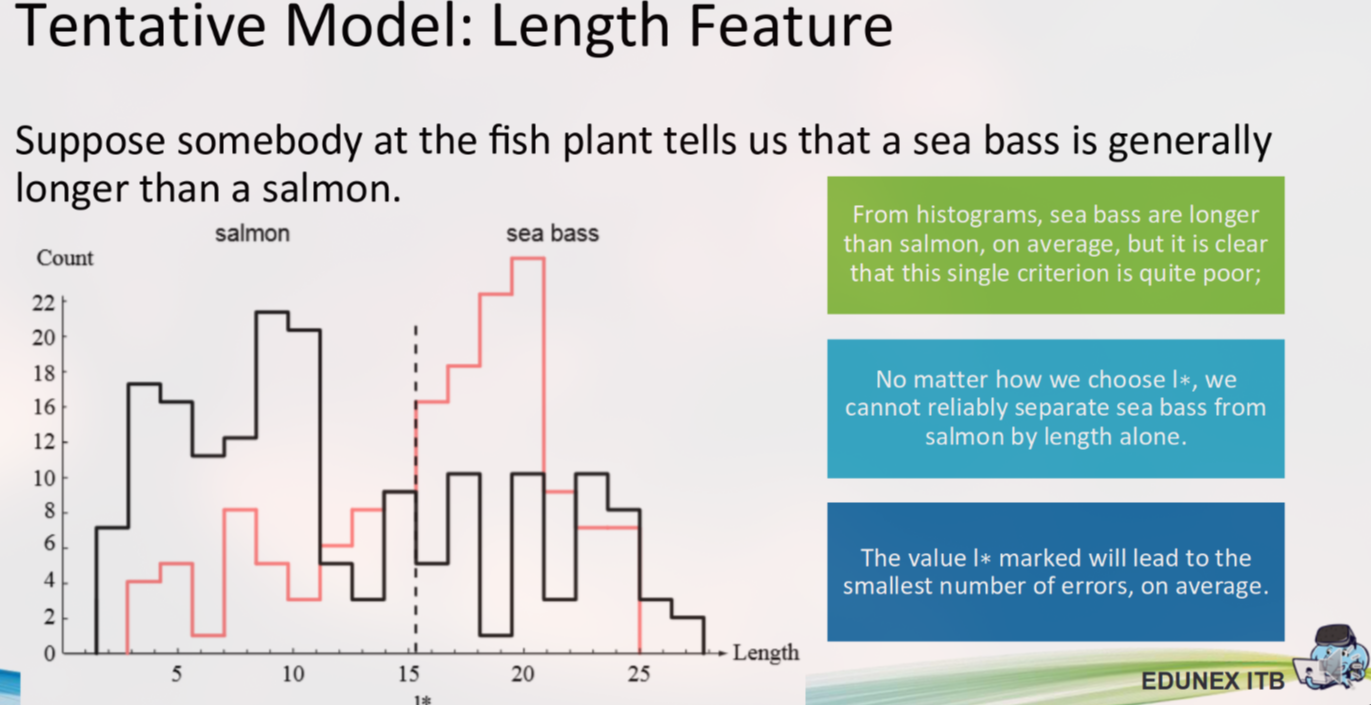
Iterasi 1: Menggunakan Satu Fitur (Panjang)
Dengan memplot histogram panjang untuk kedua kelas, terlihat bahwa meskipun rata-rata panjang Sea Bass lebih besar, distribusinya sangat tumpang tindih.
Kesimpulan: Tidak peduli di mana kita meletakkan ambang batas (
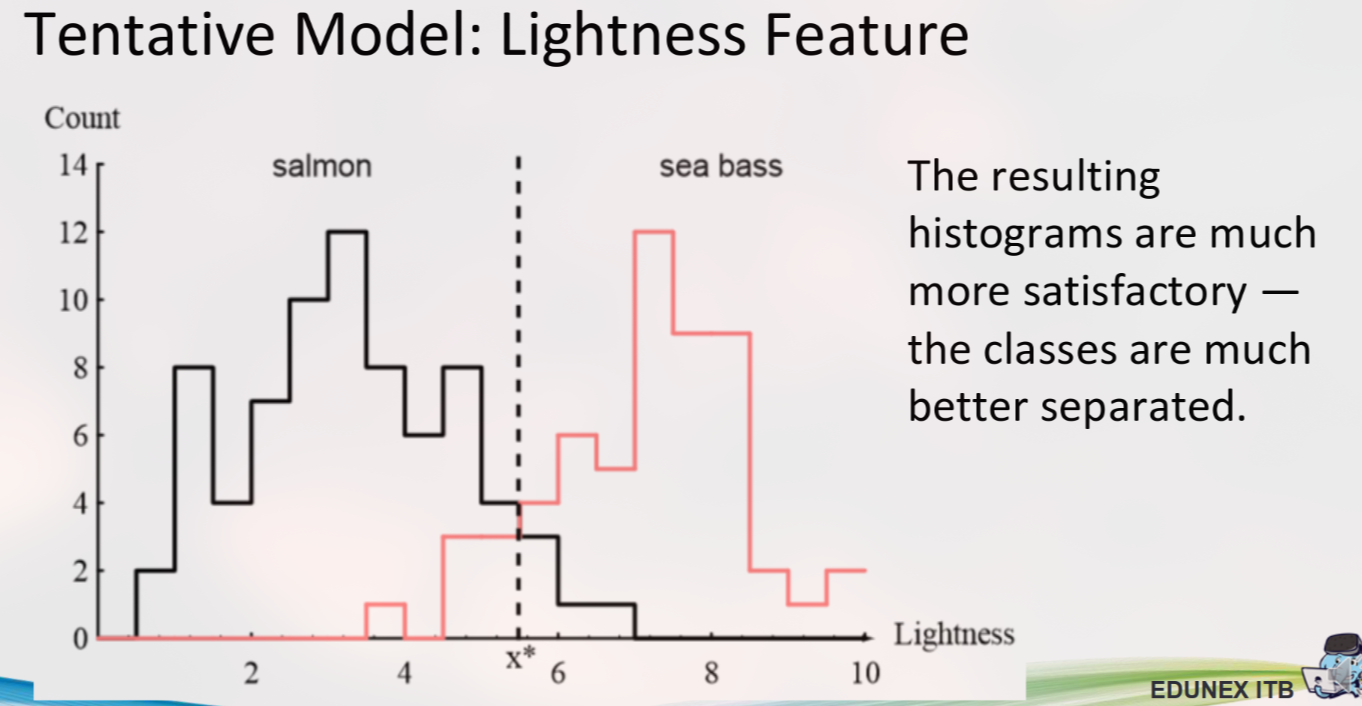
l*), akan selalu ada banyak kesalahan klasifikasi. Fitur ‘panjang’ saja adalah pemisah yang buruk.Iterasi 2: Menggunakan Satu Fitur (Kecerahan)
Histogram kecerahan menunjukkan pemisahan yang jauh lebih baik antara kedua kelas. Distribusinya tidak terlalu tumpang tindih.
Kesimpulan: Fitur ‘kecerahan’ adalah prediktor yang jauh lebih baik daripada ‘panjang’.
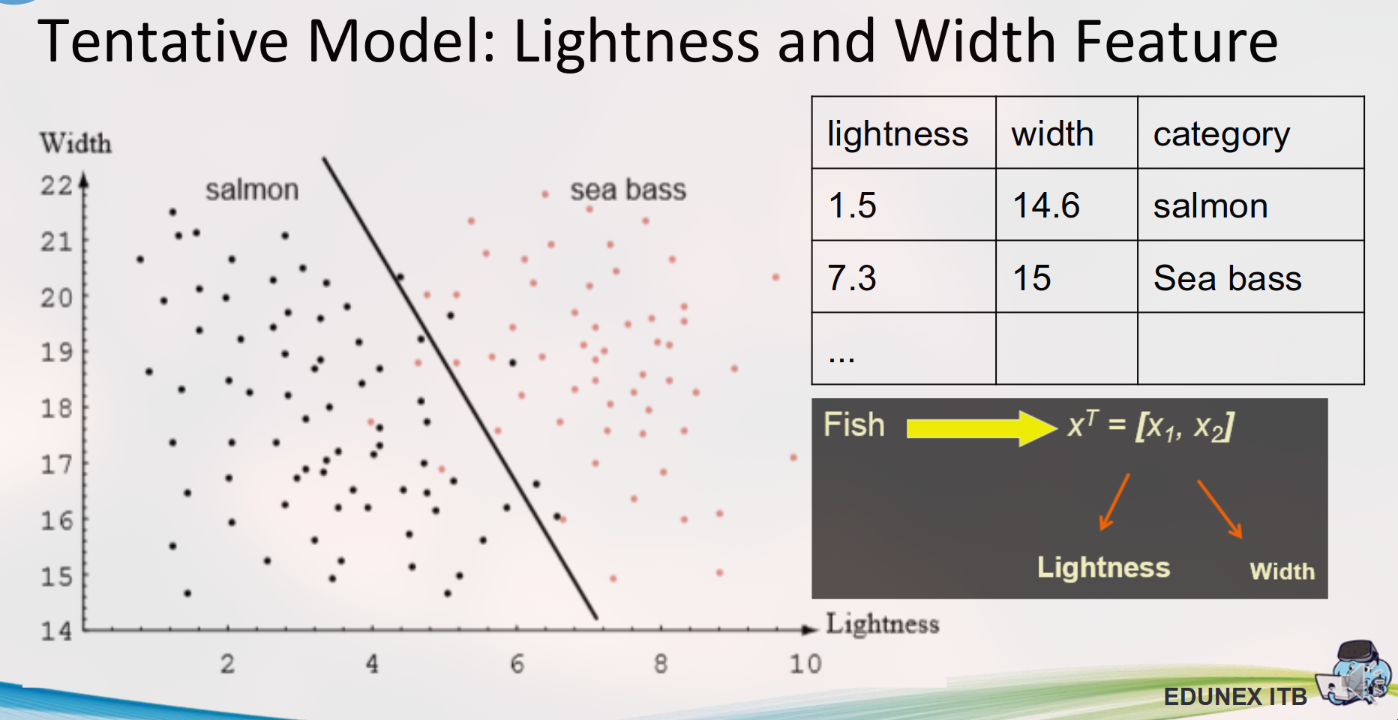
Iterasi 3: Menggunakan Dua Fitur (Kecerahan & Lebar)
Dengan menggunakan dua fitur, kita dapat memvisualisasikan data sebagai titik-titik pada plot 2D (scatter plot).
Model klasifikasi dalam kasus ini bertugas untuk menemukan sebuah garis atau kurva pemisah (Decision Boundary) yang memisahkan titik-titik data Salmon dari Sea Bass.
Dilema Kompleksitas Model: Overfitting vs. Generalisasi
Model Sederhana (misal: Garis Lurus): Mungkin membuat beberapa kesalahan pada data latih, tetapi cenderung lebih robust.
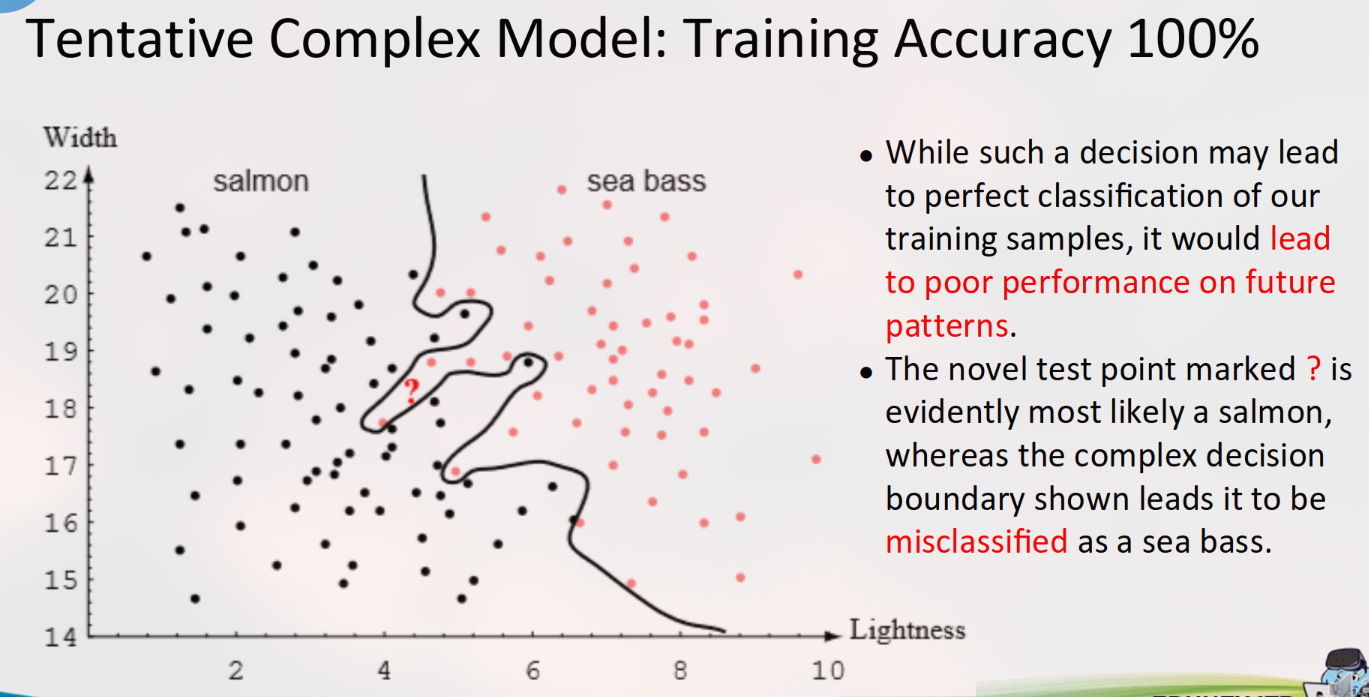
Model Sangat Kompleks: Dapat menciptakan decision boundary yang sangat berliku-liku untuk mengklasifikasikan semua titik di data latih dengan sempurna (akurasi training 100%). Namun, model ini menjadi terlalu “menghafal” data latih, termasuk noise-nya. Ini disebut Overfitting.
- Konsekuensi Overfitting: Ketika model ini dihadapkan pada data baru (yang tidak ada dalam set pelatihan), performanya akan sangat buruk. Ia gagal menangkap pola yang mendasari dan hanya menghafal contoh spesifik.
Model Optimal: Model yang baik menemukan keseimbangan. Ia cukup kompleks untuk menangkap pola yang sebenarnya dalam data, tetapi tidak terlalu kompleks sehingga ia juga menangkap noise. Model seperti ini memiliki kemampuan generalisasi (generalization) yang baik, artinya ia berkinerja baik pada data baru yang belum pernah dilihat.

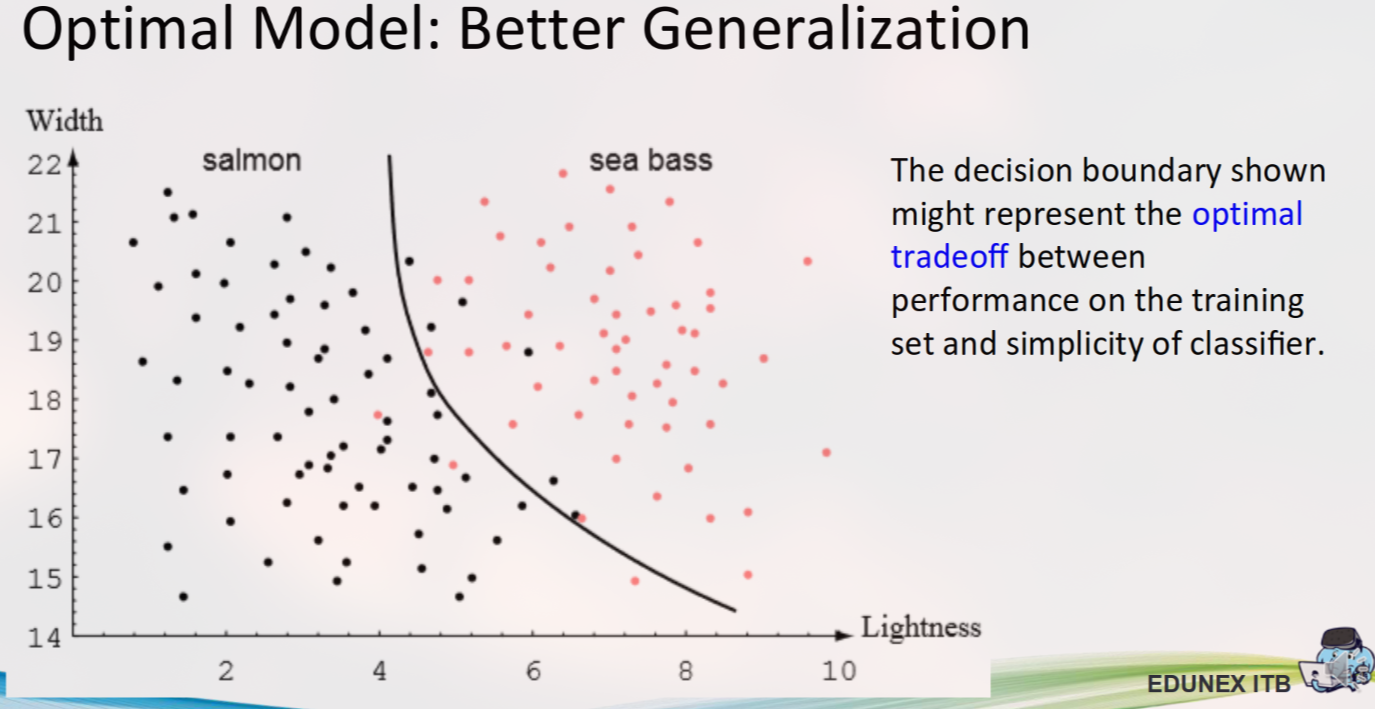
Studi kasus klasifikasi ikan menunjukkan proses supervised learning secara praktis: dimulai dari masalah nyata, membangun dataset melalui pra-pemrosesan gambar dan ekstraksi fitur yang relevan (seperti kecerahan dan lebar). Proses ini mengungkapkan pentingnya pemilihan fitur yang baik dan menyoroti dilema utama dalam pemodelan: menemukan keseimbangan antara performa pada data latih dan kesederhanaan model untuk mencapai generalisasi yang baik dan menghindari overfitting.
Additional Information
Biaya Kesalahan Klasifikasi (Cost of Misclassification)
Dalam masalah ini, ada dua jenis kesalahan:
Ikan Salmon diklasifikasikan sebagai Sea Bass (False Positive, jika “Sea Bass” adalah kelas positif).
Ikan Sea Bass diklasifikasikan sebagai Salmon (False Negative).
Dari perspektif bisnis, biaya kedua kesalahan ini mungkin tidak sama. Misalnya, jika harga jual Sea Bass kalengan lebih tinggi, maka salah melabeli Salmon yang lebih murah sebagai Sea Bass bisa merugikan reputasi dan melanggar regulasi. Sebaliknya, salah melabeli Sea Bass sebagai Salmon “hanya” menyebabkan kerugian pendapatan. Model yang baik harus mempertimbangkan biaya asimetris ini, mungkin dengan mengoptimalkan metrik seperti Precision atau Recall alih-alih akurasi saja.
The Curse of Dimensionality
Studi kasus ini menunjukkan bahwa menambahkan fitur kedua (‘lebar’) meningkatkan performa. Namun, menambahkan fitur secara membabi buta tidak selalu lebih baik. The Curse of Dimensionality adalah fenomena di mana penambahan fitur (dimensi) justru membuat data menjadi semakin renggang (sparse), sehingga jarak antar titik data menjadi kurang bermakna dan performa model bisa menurun jika jumlah data latih tidak bertambah secara eksponensial. Inilah mengapa feature selection dan feature extraction menjadi sangat penting.
Eksplorasi Mandiri
Bayangkan Anda harus menambahkan fitur ketiga, misalnya ‘tekstur sisik’. Bagaimana Anda akan memvisualisasikan data dalam 3D? Bagaimana decision boundary-nya akan terlihat? (Petunjuk: bukan lagi garis, melainkan sebuah bidang atau permukaan).
Jika Anda memiliki akses ke data dan tools, coba latih beberapa model klasifikasi (misalnya, Regresi Logistik, SVM, Decision Tree) pada dataset ini dan bandingkan decision boundary yang mereka hasilkan.
Sumber & Referensi Lanjutan:
- Buku: Richard O. Duda, Peter E. Hart, and David G. Stork, “Pattern Classification” (2nd Edition) - Buku ini adalah sumber asli dari studi kasus klasifikasi ikan dan merupakan salah satu teks fundamental dalam bidang pengenalan pola.